
티스토리 뷰
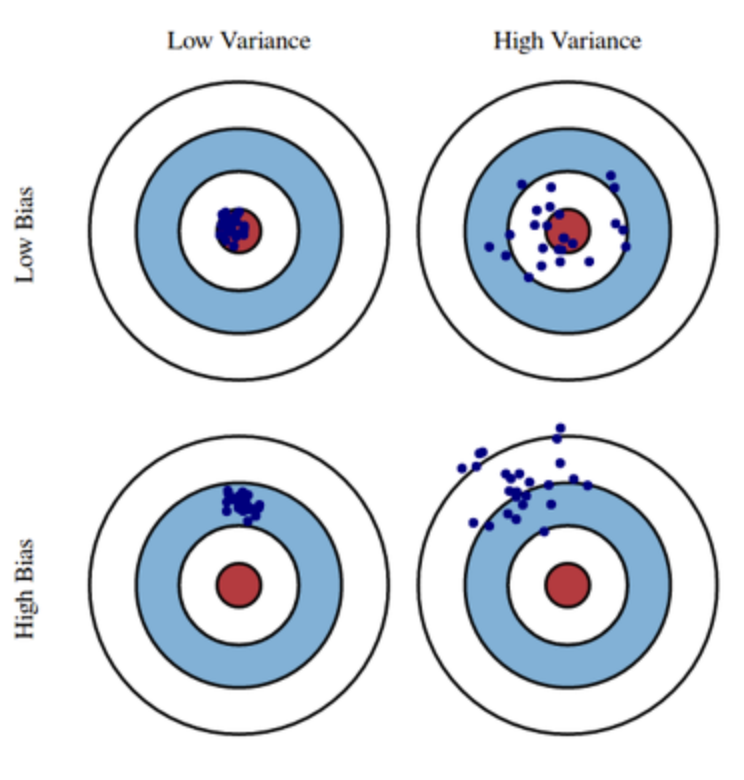
- 편향 (Bias) : 예측이 정답에서 얼마나 떨어져 있는지를 반영한다.
- 분산 (Variance) : 예측의 변동폭이 얼마나 큰지를 반영한다.
모델을 선택할 때, training data에 대해 적절히 잘 훈련되어야 하며, 새로운 데이터에 대해서 일반화 (Generalization) 까지 하는 것이 가장 이상적이라 할 수 있다. 하지만 이 둘을 동시에 달성하는 것은 거의 불가능하다.
전체 에러 수식을 보면 다음과 같다.

첫 번째 δ ^2은 절대 줄일 수 없는 오차, 두 번째는 분산, 세 번째는 편향이다. 모델 학습은 전체 에러를 낮추는 방향으로 진행 되기 때문에 전체 에러가 주어질 경우, 분산과 편향사이에 트레이드 오프가 일어나게 된다.
고분산 학습 알고리즘의 경우 training data를 잘 표현하지만 노이즈나 부적절한 training data까지 학습하여 과적합 (Overfitting) 위험이 크다. 고편향 학습 알고리즘의 경우 과적합 문제가 거의 없는 단순한 모델을 제시하지만 training data의 규칙성을 찾지 못해 과소적합 (Underfitting) 문제가 발생한다. 아래의 그래프를 보면 이해가 쉬울 것이다.

학습을 진행하는 동안 어느 순간 에러율이 감소하다가 증가하는 순간이 오게 되며, 적절한 모델을 찾아야 한다. 적절한 모델이라는 것이 결국, 분산과 편향의 균형을 고려하여 한쪽으로 치우치지 않는 최적의 복잡도를 찾는 것임을 알 수 있다.
머신 러닝들의 접근 방법
차원 축소(dimensionality reduction)와 특징 선택(feature selection)은 모형 간소화에 의해 분산을 감소시킨다. training set이 클수록 분산이 작아진다. feature를 추가할수록 추가적인 분산의 도입으로 편향이 작아진다.
- 일반 선형 모형 (Generalized Linear Model) : 편향 (Bias) 를 증가시켜 규칙화 (Regularization) 할 수 있다.
- 인공신경망 (Artificial Neural Networks) : hidden unit 갯수가 증가할수록 분산은 증가하고 편향은 감소한다.
- K-근접이웃 (K-nearest neighbor) : K가 커질수록 편향은 증가하고 분산은 감소한다.
- 의사결정나무 (Decision Tree) : 깊이 (Depth) 가 깊어질수록 분산은 증가한다. 일반적으로 분산을 제어하기 위해 Pruning을 수행한다.
References
'ML (Machine Learning)' 카테고리의 다른 글
| [Ridge, Lasso, Elastic Net] Regression (1) | 2019.06.10 |
|---|---|
| 랜덤 포레스트(Random Forest) (0) | 2019.05.15 |
| 의사 결정 나무(Decision Tree) (1) | 2019.04.23 |
| Logistic Regression (로지스틱 회귀) (0) | 2019.04.08 |
| 분류 성능 모델 평가 지표 (0) | 2019.04.07 |