
티스토리 뷰
논문
Abstract
- 문서 표현을 위해 전통적으로 BoW (Bag-of-Words) 방식을 사용하지만, 이 방식의 문제점은 높은 차원과 희소성 (Sparsity) 을 가진다는 것임.
- 최근에는, 이러한 문제를 해결하기 위해 (더 낮은 차원, Dense한 분산 표현) 을 얻기 위한 많은 방식들이 제안되었음.
- 단락 벡터 (PV, Paragraph Vector) 가 하나의 방법임.
- 단락 (Paragraph) 을 추가적인 단어로 고려하여, Word2Vec을 확장한 방법.
- 단락 벡터 (PV, Paragraph Vector) 가 하나의 방법임.
- 그러나, PV는 모든 작업에서 하나의 표현만 생성하지만, 일부 다른 작업에서는 여러 다른 표현이 필요할 수 있음.
이 논문에서, 우리는 지도 단락 벡터 (SPV, Supervised Paragraph Vector) 를 제시함.
- SPV는 클래스 레이블이 존재하는 상황에서 PV의 Task-Specific한 다른 형태임.
- 제시된 알고리즘의 이점을 증명하기 위해서, 세 가지 성능 기준 (Criteria) 이 사용됨 :
- 해석 가능성 (Interpretability)
- 구별 능력 (Discriminative Power)
- 계산 효율성 (Computational Efficiency)
Index Terms
- Class Label
- Distributed Representations
- Representation Learning
- Document Embedding
- Word Embedding
I. Introduction
- 최근까지 흔하게 사용된 문서 표현 기법은 BoW (Bag-of-Words) 였음.
- BoW의 Feature는 단어이고, 전체 Features 수는 어휘집합 (Vocabulary) 크기 또는 유일한 단어 갯수와 동일함.
- 이 경우, Feature 값은 단어의 존재, 빈도 수 또는 가중치된 각 문서의 단어 빈도 수로 채워질 수 있음.
- 하지만, 사람이 사용하는 언어의 Terms의 수는 굉장히 많고, 문서 대부분이 Terms를 특정하게 많이 포함하지 않음.
- 이렇게 만들어진 문서 벡터들은 보통 매우 고차원이며 Sparse함.
- 또 다른 Bow의 결점은 문서 Pair가 거의 직교하기 때문에, 문서 Pair 사이의 유사도를 계산하기 어려움.
이러한 문제 때문에 Dense한 표현 (분산 표현) 을 찾는 방법들이 제시됐음.
- 이 아이디어는 특히 Word2Vec, NNLM (Neural Network Language Model) 처럼 단어를 사용할 때 성공적이었음.
- PV는 Input 계층에 문서의 one-of-K 또는 원-핫 벡터를 추가하여 Word2Vec을 확장한 아키텍처이며, 따라서 단어와 문서 벡터의 공동 훈련이 가능함.
- 그러한 알고리즘들 중에서, Word2Vec과 PV는 간단함과 적용 가능성 덕분에 많은 관심을 끌었음.
- 그러나, Word2Vec, PV 둘 다 하나의 표현만 생성하는 반면, 다른 작업들에서는 다른 표현이 필요할 수 있음.

- Figure 1 (a) 에서, Word2Vec 같은 비지도 (Unsupervised) 학습 알고리즘은 보통 임베딩 공간에서 의미적, 구문론적으로 유사한 단어들을 인접하게 위치시키기 위해서 단어 벡터들을 생성함.
- 따라서, 표현 공간에서 "amazing", "awful" 같이 공통 이웃을 공유하는 단어들을 분리하기 어려움.
- 그러나, 선호하는 작업이 감성 분류 같은 지도 작업이라면, Figure 1 (b) 의 공간 내 다른 위치에 "amazing"과 "awful"과 같이 다른 극성을 가지고 있는 단어들을 분리하고 싶을 것임.
- 비지도적 상황에서 특정 지도 작업으로 단어 표현을 적용하는 것은 불가능하거나 극도로 어렵지만, 우리는 클래스 레이블을 사용하여 Task-Adaptive한 단어 표현을 얻을 수 있음.
- 여기에 사용된 가정은 자주 발생한 단어가 특정한 클래스 레이블과 함께 발생한다면, 그 단어는 그 클래스와 관련이 있다는 것임.
- 이 가정을 바탕으로 수행하는 방법은 문서 Term을 포함하여 PV를 수행하는 것처럼 Word2Vec에 클래스 레이블 Term을 추가하는 것임.
- Sachan과 Kumar는 Word2Vec의 Skip-gram 아키텍처에 클래스 레이블 Term을 추가하여 이를 수행하였음.
- 그러나, 이들의 접근법은 문서에 대한 표현을 찾을 수 없고, 분류는 Binary 클래스에 초점을 맞췄음.
이 논문에서, 우리는 단어, 문서, 클래스 레이블의 표현을 얻기 위해 PV 아키텍처를 확장함.
- 우리는 하나의 목적 함수에 관련된 모든 Terms를 포함하며, 이는 Task-Dependent한 수정을 가능하게 함.
- 제시된 알고리즘의 이점을 보여주기 위해, 우리는 세 가지 기준을 주장함 :
- 해석 가능성 (Interpretability)
- 구별 능력 (Discriminative Power)
- 계산 효율성 (Computational Efficiency)
Interpretability
- 클래스 벡터와 가깝거나 멀리 있는 단어를 찾고, 그러한 단어들이 각 클래스와 연관이 있다는 것을 증명함.
- 또한, 단어, 문서, 클래스 벡터들 사이의 관계에 대해 이해를 돕고자 이들을 임베딩 공간에 시각화함.
Discriminative Power
- Binary 분류, Multi-class 분류 까지 다루는 실제 데이터셋 몇 개를 가지고 문서 분류를 수행하고, 우리 방법이 클래스 수에 상관없이 분류 문제를 해결하고 BoW와 PV와 비교할만한 분류 정확도를 달성함.
Computational Efficiency
- 계산 효율성은 훈련 시간을 측정하여 평가함.
II. Related Work
A. Learning Distributed Representations for Documents
- 문서 표현의 전통적인 방법은 BoW임.
- 이 방법은 직관력 있지만 다음과 같은 문제점들이 있음.
- 높은 차원과 Sparse한 표현을 야기함.
- 문서 Pair 벡터가 거의 직교하기 때문에 유사성을 계산하기 어려움.
- 대신, Dense한 표현과 더 낮은 차원을 얻을 수 있는 방법들이 제시되었음.
- TDM (Term-Document matrix) 를 SVD (Singular Value Decomposition) 하는 차원 감소 기법.
- 더 복잡한 의미 또는 문서 표현을 구축하기 위해 Distributed 단어 벡터를 결합.
- 문서 표현을 직접 학습하는 방법도 있음.
- PV는 단락 또는 문서 벡터를 얻기 위해 사용될 수 있는 Word2Vec의 확장판임.
- Skip-Thought 벡터의 목적은 주변 문장을 예측하는 것임.
- Word2Vec Inversion은 분산 표현을 분류기로 변환하기 위해 베이지안 룰을 사용함.
- AdaSent는 반복적으로 계층적 표현을 얻고, BPTS (Back-Propagation Through Structure) 를 통해 훈련됨.
그러나, 이러한 방법들 대부분이 비지도 (Unsupervised) 이고, 과제에 관계없이 하나의 표현만 생성함.
- 비지도 학습이 레이블 있는 데이터가 거의 없는 상황에서는 이점이 있지만, 레이블 있는 데이터가 충분히 있을 때는 이를 사용하는 것이 더 나음.
- Sachan & Kumar는 PV의 DBOW (Distributed Bag-Of-Words) 아키텍처에서 문서 벡터를 클래스 벡터로 대체하여 클래스 레이블 벡터와 나란히 단어 벡터를 임베딩하는 아키텍처를 제시함.
- 그러나, 이 기법은 한계가 있음.
- 분류 작업에서 직접 문서를 임베딩 하는 대신, 단어 확률 점수를 선형 결합 (Linear Combinations) 함.
- 하지만, 문서 표현을 찾는 것이 유용할 수 있음.
- 예를 들어, 문서와 단어 또는 문서와 클래스 레이블 사이의 유사도를 계산할 수 있음.
- 또한, 문서, 단어, 클래스 레이블의 공동 임베딩 공간을 시각화할 수 있음.
- 점수를 매기는 모델이 Binary 분류에만 제한됨.
- 분류 작업에서 직접 문서를 임베딩 하는 대신, 단어 확률 점수를 선형 결합 (Linear Combinations) 함.
B. Document Classification
- 문서 분류는 사전에 정의되 레이블 \(C \, = \, \{c_{1}, c_{2}, ..., c_{M}\}\) 집합의 컨텐츠를 바탕으로 여기서 뽑힌 클래스 레이블 \(\hat c\) 을 할당하여, 전체 텍스트를 분류하는 작업임.
- 특히, 감성 분류는 주어진 문서의 극성을 판단하는 작업과 관련있음.
- 극성은 Binary (Positive & Negative), Ternary (Positive & Neutral & Negative), N-ary (1 ~ 5 Star).
그러나, 이전 연구들의 대부분은 Feature Engineering 또는 주어진 과제에 대한 좋은 Feature 선택에 집중되있음.
- 분류 정확도는 Feature 집합에 상당히 의존하는 것을 보여 왔으며, 좋은 Feature 집합을 위한 Feature Engineering은 많은 Man-hours를 필요로 함.
- 우리 기법은 추가적인 Feature Engineering 없이 Distributed Feature를 학습하고, 도메인 또는 언어와 관련된 어떤 지식도 필요하지 않음.
III. Word2Vec and Paragraph Vector
A. Word2Vec
- Word2Vec은 단어 임베딩 알고리즘이지만, 문서 임베딩 알고리즘인 PV의 기초가 됨.
- 특히, Word2Vec은 타겟 단어를 예측하기 위해 문맥 단어들을 사용함.

- Figure 2 처럼, Word2Vec은 두 가지 아키텍처가 있음 :
- CBOW (Continuous Bag-of-Words)
- Skip-gram
- 각 계층 벡터 및 파라미터 설명
- Input 벡터 : \(\mathbf{x} \, ∈ \, \mathbb{R}^{V\times 1}\)
- Hidden 벡터 : \(\mathbf{h} \, ∈ \, \mathbb{R}^{\delta\times 1}\)
- Output 벡터 : \(\mathbf{y} \, ∈ \, \mathbb{R}^{V\times 1}\)
- \(V\) : 어휘 집합 (Vocabulary) 크기
- \(\delta\) : 사전에 정의된 벡터 차원 크기
- \(\gamma\) : 문맥 단어 갯수
- \(\mathbf{W}^{(1)} \, ∈ \, \mathbb{R}^{V\times \delta}\) : Input 단어 임베딩 Matrices
- \(\mathbf{W}^{(2)} \, ∈ \, \mathbb{R}^{V\times \delta}\) : Output 단어 임베딩 Matrices
- \(\gamma\) 가 사전 정의된 문맥 단어 갯수면,
- CBOW는 근접한 \(\gamma\) 개 문맥 단어를 Input으로 수용하고, 타겟 단어를 예측함.
- Skip-gram은 타겟 단어를 Input으로 사용하고, 주변 \(\gamma\) 개의 문맥 단어를 예측함.
두 가지 Word2Vec 아키텍처의 특성
- Input 계층은 one-of-K 벡터로 구성되었음.
- 각 벡터의 \(i\) 번째 행은 어휘 집합에서 \(i\) 번째 단어의 존재 여부를 표현함.
- 그 다음, Hidden 계층 \(\mathbf{h}\) 의 각 유닛은 선형 활성화 함수를 이용한 Input의 가중치 합계임.
- 가중치들은 \(\mathbf{W}^{(1)}\) 로 나타냄.
- Output 계층에서, \(\mathbf{W}^{(2)}\) 는 Hidden 계층값과 곱해지며, 타겟 단어들은 Softmax 함수로 예측됨.
- 그 이후, 타겟 단어를 one-of-K 벡터로 Encoding하면, 예측값과 실제 벡터의 차이 또는 에러가 역전파 (Backpropagation) 을 통해 나올 수 있음.
- 마지막으로, Input 가중치 \(\mathbf{(W)}^{(1)}\) & Output 가중치 \(\mathbf{(W)}^{(2)}\) 는 역전파를 통해 갱신되고, 단어 벡터는 가중치 Matrices 중 하나 또는 이들을 합산 또는 연결하여 축소하여 얻어짐.
구체적으로, 단어 갯수가 \(T\), 단어들이 연속적으로 \(w_{i}\) 로 표현되는 문서 \(d\) 가 주어졌다고 해보겠음.
- 그러면, 문서는 \([w_{1}, w_{2}, w_{3}, ..., w_{T}]\) 로 표현될 수 있음.
- 그 다음, CBOW의 목적 함수는 문맥 함수를 가지고 타겟 단어 빈도의 로그 확률을 최대화하는 것임.

- 파라미터 설명
- \(\gamma\) : 문맥 단어 갯수
- \(w_{t}\) : 타겟 단어
- \(w_{t,j}\) : 문서 내 \(j\) 번째 문맥의 \(t\) 번째 단어
- 예측 확률 \(p(w_{t}|w_{t,j}\) 은 보통 다중 클래스 Softmax 분류기로 계산됨 :

- 파라미터 설명
- \(v(w_{i})\) : 단어 \(w_{i}\) 의 Input 벡터 표현 & \(\mathbf{W}^{(1)}\) 의 \(i\) 번째 행.
- \(\mathbf{v}\prime(w_{j})\) : 단어 \(w_{j}\) 의 Output 벡터 표현 & \(\mathbf{W}^{(2)}\) 의 \(j\) 번째 열.
하지만, 어휘 집합 크기가 너무 커 Softmax 계산량이 많기 때문에, 이를 극복하기 위한 몇 가지 방법이 제시됨.
- 계층적 (Hierarchical) Softmax : \(log_{2}T\) 가속화를 얻을 수 있는 Huffman tree를 구축.
- Negative Sampling : 전체 어휘 집합을 반복하여 Sampling하는 대신, 일부 Negative 예제들만을 Sampling하여 사용.
반대로, Skip-gram은 타겟 단어를 사용하여 일부 문맥단어들을 예측함.
- Skip-gram의 목적 함수는 다음과 같음 :
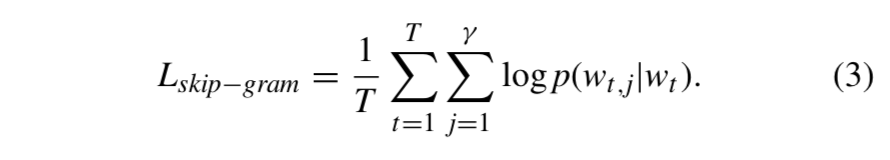
- CBOW와 Skip-gram의 Gradients는 역전파로 계산되고, SGD (Stochastic Gradient Descent) 로 최적화 됨.
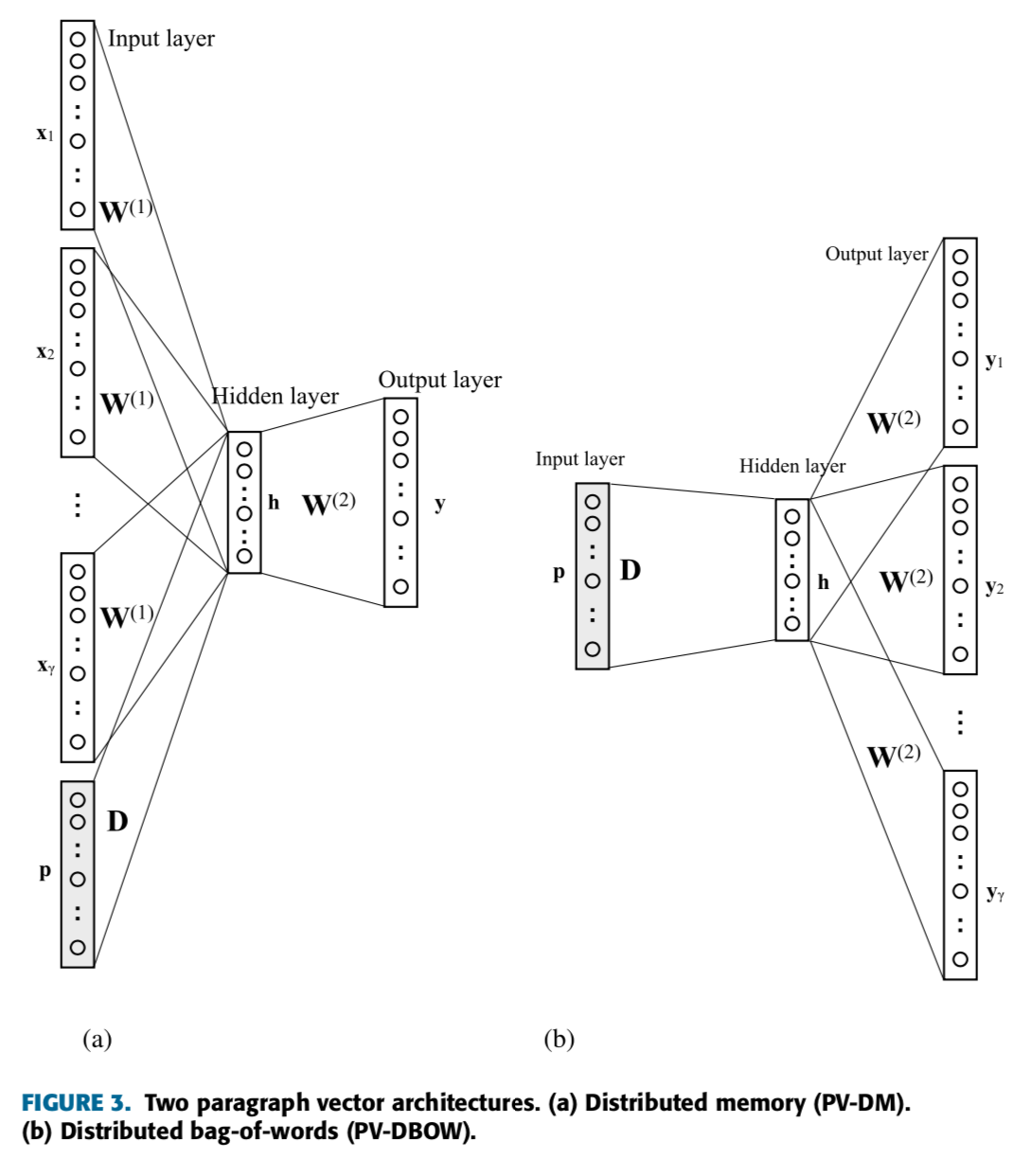
B. Paragraph Vector
- PV는 문장, 단락, 문서의 벡터 표현을 얻는데 사용될 수 있는 Word2Vec의 확장판임.
- 단어 벡터와 문서 벡터가 통합된 벡터 공간에서 함께 훈련될 수 있기 때문에, 단어-단어, 문서-문서, 단어-문서 Pair의 유사도가 계산될 수 있음.
- Word2Vec과 마찬가지로 PV에도 두 가지 아키텍처가 있음 :
- PV-DM (Paragraph Vector-Distributed Memory)
- PV-DBOW (Paragraph Vector-Distributed Bag-of-Words)
- 파라미터 설명
- \(N\) : 문서 갯수
- 해당하는 문서 벡터는 문서 임베딩 행렬 \(\mathbf{D} \, ∈ \, \mathbb{R}^{N\times \delta}\) 의 행에서 얻어짐.
- Word2Vec과 동일하게 다음과 같음 :
- Input 벡터 : \(\mathbf{x} \, ∈ \, \mathbb{R}^{V\times 1}\)
- Hidden 벡터 : \(\mathbf{h} \, ∈ \, \mathbb{R}^{\delta\times 1}\)
- Output 벡터 : \(\mathbf{y} \, ∈ \, \mathbb{R}^{V\times 1}\)
- \(V\) : 어휘 집합 크기
- \(\delta\) : 벡터 차원 크기
- \(\gamma\) : 문맥 단어 갯수
- \(\mathbf{W}^{(1)} \, ∈ \, \mathbb{R}^{V\times \delta}\) : Input 단어 임베딩 Matrices
- \(\mathbf{W}^{(2)} \, ∈ \, \mathbb{R}^{V\times \delta}\) : Output 단어 임베딩 Matrices
PV-DM에서, 문서를 이용한 타겟 단어 예측을 나타내는 로그 확률 log \(p(w_{t}|d)\) 은 CBOW 목적 함수에 추가됨 :

PV-DBOW는 Word2Vec의 Skip-gram 아키텍처 확장판이며, 로그 확률 log \(p(w_{t,j}|d)\) 도 목적 함수에 추가됨 :

IV. Supervised Paragraph Vector (SPV)
A. Representation Learning
- SPV는 Input, Hidden, Output 계층이 각 한 개씩 있는 간단한 신경망을 사용하는 단어, 문서, 클래스 레이블 임베딩 알고리즘임.
- Input 계층의 각 뉴런은 실제 단어 (Actual Words) 를 나타냄.
PV와 SPV의 가장 큰 차이점은 문서의 클래스 레이블 정보가 사용된다는 것임.
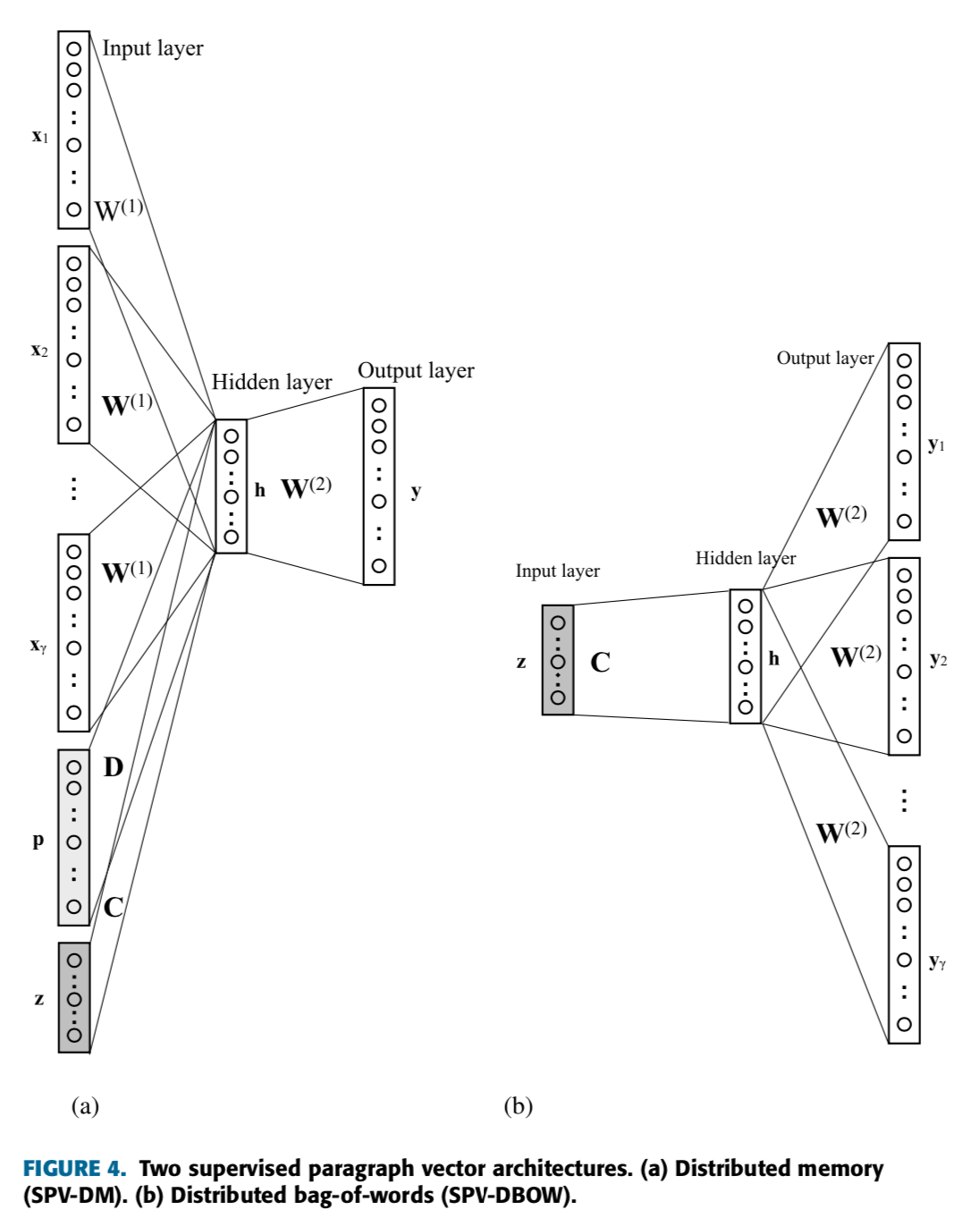
- 클래스 레이블은 Input 계층 \(\mathbf{z} \, ∈ \, \mathbb{R}^{M\times 1}\) 에서 one-of-K 벡터로 표현됨.
- \(M\) : 중복 되지 않은 유일한 클래스 레이블 갯수
- 이에 해당되는 클래스 벡터들은 클래스 레이블 임베딩 행렬 \(\mathbf{C} \, ∈ \, \mathbb{R}^{M\times \delta}\) 의 행임.
- Word2Vec & PV와 동일하되, 일부 추가된 것만 적겠음 :
- 문서 벡터 : \(\mathbf{p} \, ∈ \, \mathbb{R}^{N\times 1}\)
- 문서 임베딩 Matrics : \(\mathbf{D} \, ∈ \, \mathbb{R}^{N\times \delta}\)
- 문서 벡터가 벡터의 구성요소 (Constituents) 단어 시퀀스로 예측하여 얻을 수 있다고 가정하는 PV 처럼, SPV도 클래스 벡터가 벡터의 구성 요소 시퀀스를 예측하여 얻을 수 있다고 가정함.
- 이러한 이유는 넓은 의미에서, 클래스가 더 큰 문서 (해당 클래스의 모든 문서들을 합쳐서 만든 것) 로 간주될 수 있기 때문임.
- 이러한 관점에서, SPV의 목적 함수는 PV의 목적 함수에 추가적인 Term을 사용하여 정의될 수 있음.
- SPV_DM의 목적함수는 아래와 같음 :
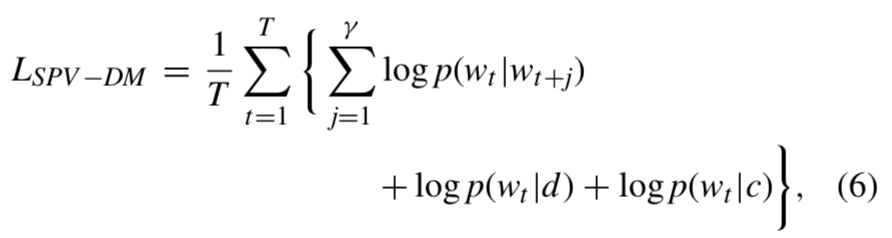
- 파라미터 설명
- \(c\) : 문서 클래스
- 나머지는 위에서 설명
- 유사하게, SPV-DBOW의 목적 함수도 다음과 같음 :

- Word2Vec & PV와 마찬가지로, SPV의 파라미터들은 SGD를 이용하여 찾고, Gradients는 역전파를 통해 얻어짐.
- 그러나, SPV-DBOW를 이용할 때, \(\mathbb{C}\) 는 모든 단어, 문서, 클래스 레이블을 훈련하기 위해 \(\mathbb{D}\) 또는 \(\mathbb{W}^{(1)}\) 로 대체할 수 있음.
- 문서 벡터와 클래스 벡터와 마찬가지로, 문맥 & 타겟 단어 벡터들은 학습 과정에서 무작위 또는 순차적으로 선택될 수 있음.
B. Inference and Classification
- 표현 모델이 훈련된 후에, 단어, 클래스 레이블, 훈련 집합 문서 표현이 얻어짐.
- 하지만, 테스트 집합의 문서를 분류하기 위해서, 관찰되지 않은 문서에 대한 표현을 얻어야 함.
- 이를 추론 단계 (Inference Step) 이라고 부름.
Inference Step
- 이전에 훈련된 표현 모델을 사용하여 각 테스트 문서에 대한 벡터들을 계산함.
- Training Step과 Inference Step의 차이점은 목적 함수에서 클래스 조건부 (Conditional) Term이 무시된다는 것임.
- 왜냐하면, 테스트 집합 각 문서의 진짜 클래스를 모르기 때문임.
- 또한, Training Stage에서 얻은 클래스 벡터, 단어 벡터, Softmax 가중치들은 갱신되지 않으며, 이는 Test 동안 고정된다는 것을 의미함.
- 이 과정을 통해 테스트 문서에 대한 표현을 얻은 후에, 두 가지 방법으로 문서들을 분류할 수 있음.
- 훈련과 테스트 문서에 대한 \(\delta\) 차원의 벡터들을 이미 가지고 있기 때문에, 또 다른 분류기의 Input으로 문서 벡터를 사용하는 것임.
- 그런 다음, 이러한 벡터들을 분리된 분류기 알고리즘 (ex. 로지스틱 회귀) 에 Input으로 집어넣을 수 있음.
- 문서 벡터와 모든 클래스 벡터 사이의 코사인 유사도 또는 다른 적절한 유사도 측정치를 계산하고, 예측된 문서 클래스와 가장 가까운 클래스를 선택하는 것임.
- 훈련과 테스트 문서에 대한 \(\delta\) 차원의 벡터들을 이미 가지고 있기 때문에, 또 다른 분류기의 Input으로 문서 벡터를 사용하는 것임.
- SPV를 이용한 전체 문서 분류 과정은 Table 1에 제시됨.

V. Experiments
A. Criteria for Performance Evaluation
- 문서 표현을 평가하기 위해서, 세 가지 기준을 선택함 :
- 해석가능성 (Interpretability)
- 구별 능력 (Discriminative Power)
- 효율적인 계산 (Efficient Computation)
첫 번째로, 우리가 문서 표현 자체에서 Insights를 얻을 수 있다는 것이 중요함.
- 이러한 종류의 \(Interpretability\) 는 정성적 척도이며, 시각화 및 예시로 증명됨.
두 번째로, 좋은 문서 표현 알고리즘은 문서와 또 다른 문서를 구별함.
- 일부 거리 Metric이 주어지면, 유사한 컨텐츠를 가진 문서들은 더 짧은 거리를 가져야 하지만, 서로 다른 컨텐츠를 가진 문서들은 더 긴 거리를 가져야 함.
- 우리는 이것을 \(Discriminative \, Power\) 라고 부르며, 분류 정확도는 대리 (Proxy) 척도로 사용될 수 있음.
세 번째로, 좋은 문서 표현 알고리즘은 빠르게 표현을 계산함.
- 따라서, \(Efficient \, Computation\) 은 또 다른 중요 기준임.
- 이는 훈련 시간으로 측정될 수 있음.
사전 정의된 세 가지 기준들 외에도, Reconstructing Quality 기준 또한 표현을 평가할 수 있음.
- 이는 표현이 원래 형태로 바뀔 수 있는지 여부를 나타냄.
- 그러나, 이 논문에서 비교된 알고리즘은 기본적으로 BoW 가정을 사용하기 때문에, Reconstruction은 고려하기 어려움.
B. Datasets
- 실험에서 사용된 데이터셋은 다음과 같음 :

C. Implementation
- 첫 번째로, 제시된 알고리즘과 다음 알고리즘들을 비교했음 :
- BOW-TF (Bag-of-Words with Term Frequency)
- BOW-TFIDF (Bag-of-Words with Term Frequency with Inverse Document Frequency)
- 효율적인 계산과 더 좋은 일반화를 위해 BOW 모델의 Terms 수는 100개로 제한함.
- 또한, 두 개의 PV 아키텍처와도 성능을 비교했음 (PV-DM & PV-DBOW).
- PV, SPV의 하이퍼파라미터 대부분을 동일하게 설정함.
- 구체적으로, 벡터 차원 (\(\delta\)) : 100.
- 각 단어는 20개의 문맥 단어 (\(\gamma\)) (또는 윈도우 크기 10) 로 훈련되며, 5보다 작은 Term Frequency를 가지는 단어는 무시됨.
- 빈발적인 Terms는 확률 \(P(w_{i}) \, = \, 1 \, - \, \sqrt{τ \, / \, f(w_{i})}\) 에 의해 버려짐.
- \(f(w_{i})\) : Term Frequency
- \(τ\) : 0.001로 설정된 임계값 (Threshold Value)
- 5개의 Noise 단어를 이용한 Negative Sampling이 사용됨
- Table 3에 실험에 사용된 각 하이퍼파라미터 값들이 요약되있음 :

- 각 문서마다 표현을 찾은 후에, 분류기 5개를 적용했음 :
- DT (Decision Tree)
- LR (Logistic Regression)
- RF (Random Forest)
- NN (Neural Network)
- NB (Naive Bayes)
분류기 설정
- DT : 분리를 결정하기 위해 지니 불순도를 사용함.
- LR : \(L_{2}\) 패널티를 사용함.
- RF : 10개의 트리를 가지고 지니 불순도를 사용함.
- NN : 100개 뉴런을 가진 Hidden 계층 한 개, ReLU (Rectified Linear Unit) 활성 함수를 사용함.
- NB : 특별히 사용하는 하이퍼파라미터 없음.
분류기의 효과를 최소화하고, 아키텍처 간 공평한 비교를 수행하기 위해 각 분류기를 동일하게 설정했음.
- 그렇지만, 실제 배치 동안은 최적의 하이퍼파라미터를 결정하는 분리된 검증 집합을 사용하는 것을 추천함.
- 마지막으로, 테스트 집합의 분류 정확도는 성능 측정을 위해 사용됨
D. Experimental Results
Interpretability
- 각 클래스 벡터와 가장 가깝고 먼 단어들을 찾음.
- 여기서, 우리는 클래스 레이블과 단어들을 100차원 공간에 임베딩한 imdb 데이터셋을 사용하고, 코사인 유사도를 사용함.
- 또한, 빈도도가 100보다 작은 단어들을 제거함.
- Table 4는 각 Positive, Negative 감성을 가진 단어들이 그 클래스 레이블과 더 가깝다는 것을 보여줌.
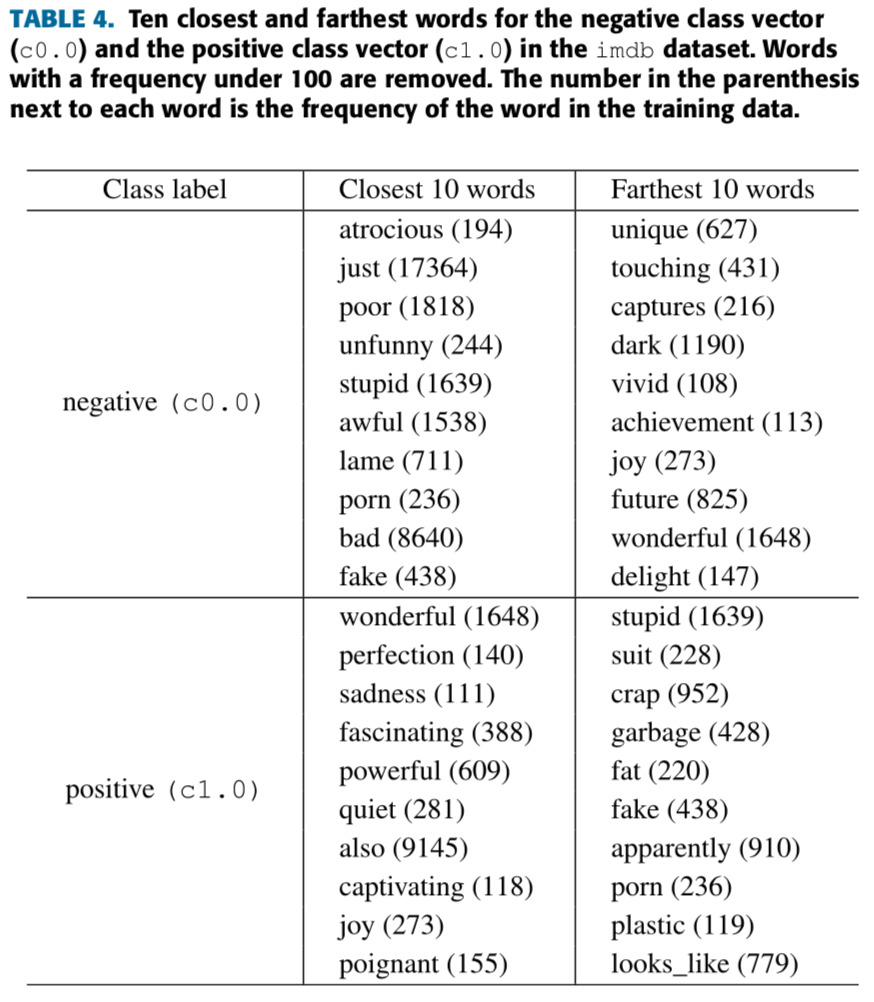
- 이 방법은 PV의 비지도 버전에는 적용할 수 없음.
- 왜냐하면, 클래스 레이블 벡터가 존재하지 않기 때문임.
- 다음으로, PV와 SPV에 대해 Inter-class, Intra-class 유사도 차이를 비교함.
- Inter-class 유사도 : 서로 다른 클래스를 가진 두 개의 단어들 사이의 평균 거리
- Intra-class 유사도 : 동일한 클래스를 가진 두 개의 단어들 사이의 평균 거리
- 각 유사도 측정은 (8), (9) 을 이용함 :

- 파라미터 설명
- \(\mathbb{1}\) : Indicator 함수
- \(c_{i}\) : 주어진 클래스 \(i\) 의 단어 집합
- \(N_{k}\) : 주어진 조건 \(k\) 에 대한 질적인 (Qualified) 단어 총 갯수
- \(s(w, v)\) : 단어 \(w\) 와 \(v\) 사이의 코사인 유사도
- Intra-class 유사도가 크고, Inter-class 유사도가 작으면, \(s_{diff} \, = \, s_{intraclass} \, - \, s_{interclass}\) 는 크다는 것은 명백함.
- 다음과 같은 단어 집합들을 고려해보겠음 :
- Positive 단어 집합 : \(c_{pos} \, =\) {"wonderful", "awesome", "fascinating"}
- Negative 단어 집합 : \(c_{neg} \, =\) {"lame", "awful", "bad"}

- 그래프 설명
- 회색 : 무작위로 선택된 단어
- 초록색 : 증명한 방법으로 선택된 단어들
- 파란색 : 문서 벡터
- 빨간색 : 클래스 벡터
Discriminative Power
- 문서 분류를 수행하고 분류 정확도를 측정함.
- Table 5는 BOW, PV, SPV의 분류 정확도를 보여줌.

- 제시된 기법의 강건함을 정의하기 위해, Table 6에서 다양하고 간단한 분류기를 사용하여 실험 결과들을 제공함.

우리의 의도는 SPV가 가장 좋은 문서 표현 알고리즘이라고 논쟁하려는 것이 아니라는 것임.
- 많은 최신 문서 표현 기법들이 여러 문서 분류 작업에서 더 높은 정확도를 얻음.
- 그러나, SPV는 PV와 비교하여, 숨겨진 레이블 정보 덕분에 더 높은 분류 정확도를 얻음.
- 또한, 실제 클래스 레이블 표현을 얻음으로써, 클래스 레이블과 단어, 문서 사이의 거리를 측정할 수 있음.
- 이러한 점은 우리가 가지고 있는 데이터에 대해 많은 암시들을 제공함.
- 이는 문서 표현의 해석가능성 측면에서 굉장한 이점임.
E. Sensitivity Analysis and Computation Time
- Figure 7은 LR 분류기와 imdb 데이터셋을 사용하여, 표현 알고리즘의 훈련 시간과 문서 수, 분류 정확도 사이의 관계를 보여줌.

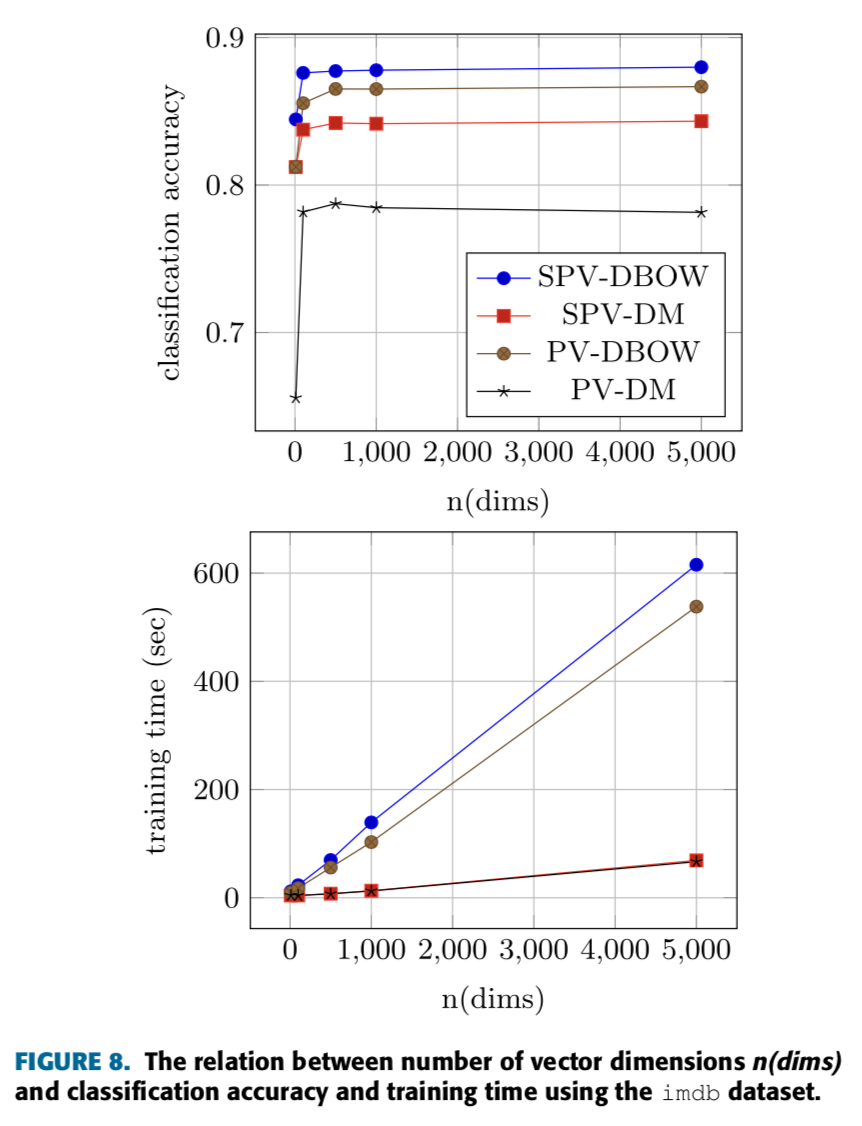
- Figure 8은 훈련 시간, 분류 정확도, 벡터 차원의 수 사이의 관계를 보여줌.
- 마지막으로, Table 7은 Imdb 데이터셋의 테스트 문서에 대한 총 Inference 시간을 보여줌.

VI. Conclusion
- 동일한 공간에 공동으로 단어, 문서, 클래스를 임베딩하는 방법인 SPV를 제시했음.
- 다음과 같이 수행하여 알고리즘의 이점을 증명했음.
- 클래스 벡터와 가깝고 먼 단어들을 발견
- Intra-class, Inter-class 유사도 사이의 차이를 계산
- 단어, 문서, 클래스의 공동 공간을 시각화
- 이는 해석가능성 측면에서 이점을 가지며, 이전 비지도 기법에서는 하지 못한 것임.
- 또한, 클래스 레이블 관리 (Supervision) 가 훈련 시간을 약간 증가시키고, 문서 벡터들의 구별 능력도 증가시킨다는 것을 보여줬음.
- 그러나, SPV를 가지고 얻은 표현에서 원래 문서를 Reconstruct를 시도할 때, BOW 가정 때문에 단어의 순서를 잃어버리기 때문에, 품질은 낮아질 수 있음.
- 동일한 이유로, SPV는 단어의 연속적인 정보를 포함하는 최신 알고리즘과 비교하여 가장 좋은 정확도를 달성하는 알고리즘이 아님.
- 일반적으로 언급된 것처럼, 종종 레이블이 있는 데이터를 얻는 것은 어려우며, PV의 이점 중 하나는 완전히 비지도라는 것임.
- 그러나, 레이블이 있는 데이터가 존재할 때, 표현 모델에 이 정보를 사용하는 것이 가장 좋을 것이며, 이것이 SPV의 핵심임.
- SPV의 훈련과정에 레이블이 없는 대규모 문서 집합을 사용할 수 있는 준지도 버전이 세 번째 기법이 될 수 있음.
- 이 경우, 레이블이 없는 문서에 더미 클래스 레이블을 할당함.
- 예를 들어, 작업이 두 가지 레이블 1 (Positive), -1 (Negative) 을 가진다면, Neutral 또는 레이블이 없는 문서에 대해 0이라 말하는 또 다른 클래스를 만듬.
- 나머지 Training 과정은 원래 알고리즘과 동일함.
- 마지막으로, SPV는 다양한 어플리케이션에서 수정될 수 있음.
- 예를 들어, "Class Labels"는 분류 작업에서 반드시 레이블이 될 필요가 없음.
- 하지만, 문서들을 설명하는 다중 "Tags" 가 될 수 있음.
- 예를 들어, 한 유저가 쓴 모든 리뷰를 종합하여 "User Vectors"를 찾고, 유저 유사도를 계산하거나 유저 프로필에 대해 그러한 벡터들을 추가로 사용할 수 있으며, 추천 과제에 알고리즘을 적용하는 시도를 할 수 있음.
'Paper > NLP' 카테고리의 다른 글
| Attention Is All You Need (0) | 2020.02.16 |
|---|---|
| BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (0) | 2019.08.10 |