
티스토리 뷰
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
기내식은수박바 2019. 8. 10. 14:42논문
Abstract
- 우리는 BERT라 부르는 새로운 언어 표현 모델을 소개함.
- 트랜스포머 양방향 인코더 표현 (BERT, Bidirectional Encoder Representations from Transformers)
- 최신 언어 표현 모델들과는 다르게, BERT는 모든 계층에서 왼쪽 & 오른쪽 문맥을 함께 조정하여 레이블이 없는 텍스트에서 심층 양방향 표현을 Pre-training 하기 위해 설계됨.
- 결과적으로, Pre-train된 BERT 모델은 Task-Specific을 위해 상당한 아키텍처 수정없이, 다음과 같은 광범위한 작업에 대해 최신 모델을 만들기 위해 한 개의 Output 계층만 추가하여 Fine-tuning 할 수 있음.
- 질문 답변 (QA, Question Answering)
- 언어 추론 (Language Inference)
1. Introduction
- 언어 모델을 Pre-training 하는 것은 많은 자연어 처리 과제를 향상시키는 데 효과적이었음.
- Pre-Training된 언어 표현을 다운스트림 (Downstream) 과제에 적용하는 두 가지 전략이 있음 :
- \(Feature\)-\(based\)
- \(Fine\)-\(tuning\)
Feature-based Approach
- 이러한 접근의 한 예시로 ELMo가 있으며, 이 방법은 추가 Feature 역할을 하는 Pre-training된 표현을 포함하는 Task-Specific 아키텍처를 사용함.
Fine-tuning Approach
- Generative Pre-trained Transformer (OpenAI GPT) 같은 이 방법은 최소한의 Task-Specific 파라미터들을 도입하고, Pre-training된 모든 파라미터를 간단히 Fine-tuning하여 다운스트림 작업에서 훈련됨.
이 두 가지 방법은 Pre-training 동안 동일한 목적 함수를 공유하는데, 일반적인 언어 표현을 학습하기 위해 단방향 언어 모델을 사용함.
- 우리는 현재 기법들, 특히 Fine-tuning 접근이 Pre-training된 표현들의 힘을 제한한다고 주장함.
- 핵심적인 제한은 표준 언어 모델이 단방향이고, 이러한 점이 Pre-training동안 사용될 수 있는 아키텍처의 선택을 제한한다는 것임.
- 예를 들어, OpenAI GPT에서, 저자들은 left-to-right 아키텍처를 사용하며, 이는 각 토큰이 트랜스포머의 Self-attention 계층에서 이전 토큰에만 참여할 수 있는 구조임.
- 그러한 제한들이 문장-수준 과제들에 Sub-optimal 하며, 양방향 Context를 통합하는 것이 중요한 QA 같은 토큰-수준 과제에 Fine-tuning기반 방법을 적용할 때, 매우 안 좋을 수 있음.
이 논문에서는 BERT를 제시하여, Fine-tuning 기반 접근법을 향상시킴.
- BERT는 "MLM (Masked Language Model)" Pre-training Objective를 사용하여, 이전에 언급한 단방향 제약을 완화시킴.
- MLM은 Input으로 들어온 토큰의 일부를 무작위로 마스크 씌우며, Objective는 마스크로 가려진 단어의 Context만을 바탕으로 이 단어의 원래 어휘집합 id를 예측하는 것임.
- left-to-right 언어 모델 Pre-training과는 달리, MLM Objective는 왼쪽 & 오른쪽 Context를 합쳐 표현할 수 있음.
- 이러한 점은 심층 양방향 트랜스포머를 Pre-training 할 수 있게 해줌.
- MLM 이외에도, 공동으로 텍스트-Pair 표현을 Pre-training 하는 "Next Sentence Prediction" 작업도 사용함.
2. Related Work
2-1. Unsupervised Feature-based Approaches
- 적용 가능한 단어 표현을 학습하는 방법은 활발한 연구 영역이 되었음.
- Pre-training된 단어 임베딩은 현대 NLP 시스템의 필수적인 부분이며, 처음부터 학습되는 임베딩보다 상당한 개선점을 제공함.
- 단어 임베딩 벡터를 Pre-training하기 위해, left-to-right 언어 모델링의 Objectives 뿐만 아니라 왼쪽 & 오른쪽 Context의 잘못된 단어들에서 올바른 단어들을 구별하는 Objectives 도 사용됨.
- 문장 표현을 훈련하기 위해서, 이전 작업들에서는 다음과 같은 Objectives를 사용했음 :
- 다음 후보 문장들에 순위를 매김
- 이전 문장 표현이 주어지면 다음 문장 단어를 left-to-right 생성
- Objectives에서 파생된 Autoencoder를 Denoising
ELMo와 이전 기법은 서로 다른 차원에 따라 전통적인 단어 임베딩 연구를 일반화함.
- 이 방법들은 left-to-right & right-to-left 언어 모델에서 \(context\)-\(sensitive\) Features를 추출함.
- 각 토큰의 문맥적 표현은 left-to-right & right-to-left 표현의 연결로 나타남.
- 기존 Task-Specific 아키텍처를 이용하여 문맥과 관련된 단어 임베딩을 통합할 때, ELMo는 일부 중요한 NLP Benchmarks를 위해 최신 기술들을 진보시킴.
- Question Answering
- Sentiment Analysis
- Name Entity Recognition
- Melamud 등은 LSTM을 이용하여 왼쪽 & 오른쪽 문맥 모두에서 단일 단어를 예측하는 작업을 통해, 문맥과 관련된 표현 학습을 제시함.
- ELMo와 유사하게, 그들의 모델은 Feature-based 이며, 양방향성이 깊지 않음.
- Fedus 등은 Cloze 작업이 텍스트 생성 모델의 강건함을 향상시키는데 사용될 수 있음을 보여줌.
2-2. Unsupervised Fine-tuning Approaches
- Feature-based 접근과 마찬가지로, Fine-tuning의 첫 번째 작업은 레이블이 없는 텍스트를 이용하여 단어 임베딩 파라미터를 Pre-training만 수행함.
- 더 최근에는, Contextual 토큰 표현을 생성하는 문장 또는 문서 Encoders가 레이블이 없는 텍스트로 Pre-training 되고, 지도 다운스트림 작업에 대해 Fine-tuning 됐음.
- 이러한 접근법의 이점은 처음부터 학습될 파라미터가 거의 필요하지 않다는 것임.
- 이러한 이점 때문에, OpenAI GPT가 많은 문장-수준 작업에서 최신 결과를 달성했음.
- Left-to-Right 언어 모델링과 Autoencoder Objectives는 그러한 모델을 Pre-training 하는데 사용됨.
2-3. Transfer Learning from Supervised Data
- 대규모 데이터셋을 이용한 자연어 추론, 기계 번역 같은 지도 작업에서 효과적인 전이 (Transfer) 를 보여주는 작업이 있음.
- 또한, 컴퓨터 비전 연구는 대규모로 Pre-training된 모델을 통해 전이 학습의 중요성을 증명해 왔음.
3. BERT
- 우리 프레임워크에는 두 가지 단계가 있음 :
- \(Pre\)-\(training\)
- \(Fine\)-\(tuning\)
- Pre-training 동안, 모델은 서로 다른 Pre-training 작업을 통해 레이블이 없는 데이터로 훈련됨.
- Fine-tuning의 경우, BERT 모델은 먼저 Pre-training 된 파라미터들로 초기화 되며, 모든 파라미터들은 다운스트림 작업에서 레이블이 있는 데이터를 사용하여 Fine-tuning 됨.
- 모델들이 동일하게 Pre-training된 파라미터로 초기화됐더라도, 각 다운스트림 작업마다 Fine-tuning된 모델을 별도로 가짐.

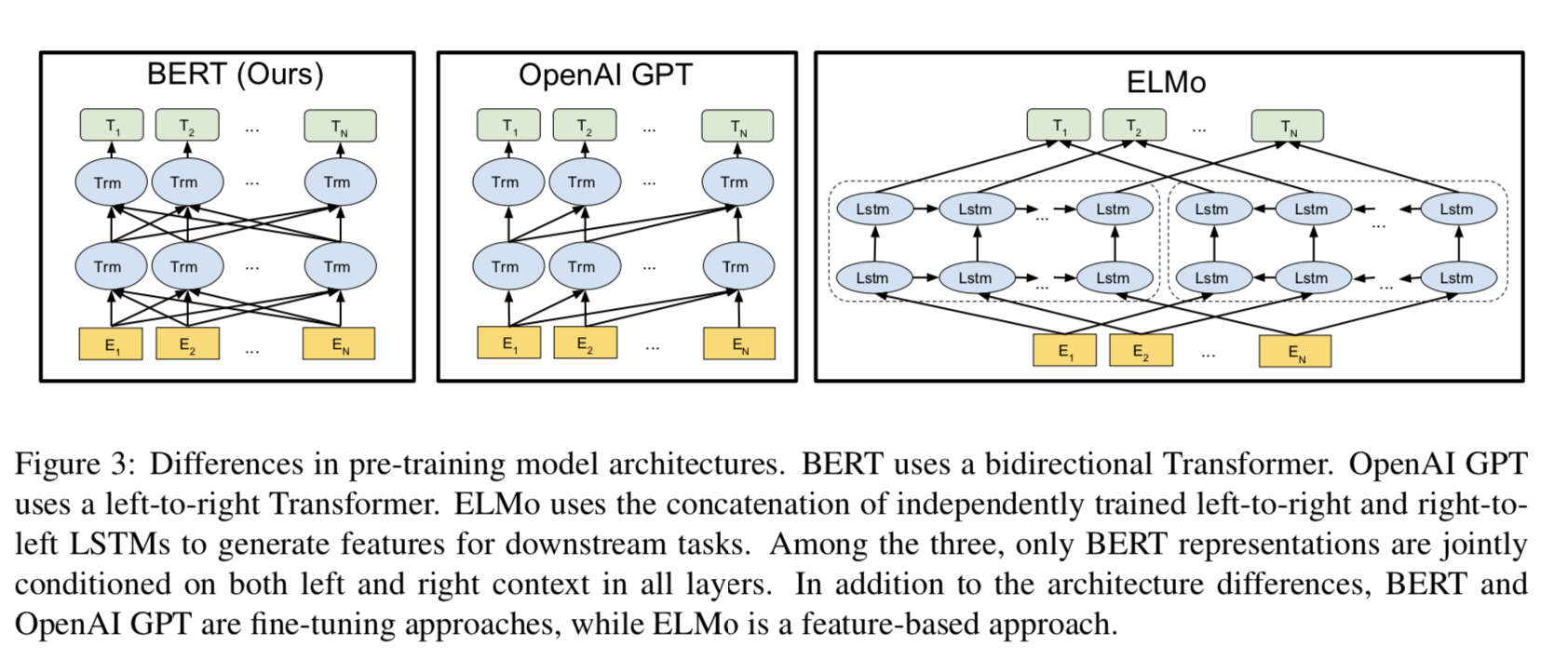
BERT의 뚜렷한 특징은 서로 다른 작업 전반에 걸친 통합된 아키텍처임.
- Pre-training된 아키텍처와 최종 다운스트림 아키텍처 사이는 아주 작은 차이가 있음.
Model Architecture
- BERT 모델 아키텍처는 다중 계층 양방향 트랜스포머 Encoder임.
- 이 연구에서, 우리는 다음과 같이 파라미터를 나타낼 것임 :
- \(L\) : 계층 갯수 (즉, 트랜스포머 블록)
- \(H\) : Hidden 크기
- \(A\) : Self-attention Heads 수
- 우리는 주로 두 가지 모델 크기로 결과를 기록함 :
- \(\mathbf{BERT}_{\mathbf{BASE}}\) (L = 12, H = 768, A = 12, 총 파라미터 수 = 110M)
- \(\mathbf{BERT}_{\mathbf{LARGE}}\) (L = 24, H = 1024, A = 16, 총 파라미터 수 = 340M)
- \(\mathbf{BERT}_{\mathbf{BASE}}\) 는 OpenAI GPT와 비교하기 위해, 이와 동일한 모델 크기를 가짐.
- 그러나, BERT 트랜스포머는 양방향 Self-attention을 사용하는 반면, GPT 트랜스포머는 모든 토큰이 자신의 왼쪽 Context에만 참여할 수 있는 제한된 Self-attention을 사용함.
Input / Output Representations
- 다양한 다운스트림 작업을 다루는 BERT를 만들기 위해, Input 표현은 하나의 토큰 시퀀스의 단일 문장과 문장 Pair (즉, <Question, Answer>) 둘을 명확하게 표현할 수 있음.
- 이 작업을 통해, "Sentence"는 실제 언어적 문장이 아닌, 인접한 임의의 범위 내 텍스트가 될 수 있음.
- "Sequence"는 BERT의 Input 토큰 시퀀스를 참조하며, 이는 단일 문장 또는 두 개의 문장이 함께 묶인 것일 수 있음.
우리는 3만 개의 토큰 어휘집합을 가진 WordPiece 임베딩을 사용함.
- 모든 시퀀스의 첫 번째 토큰은 항상 특별 분류 토큰이 됨 ([CLS]).
- 이 토큰에 해당하는 최종 Hidden State는 분류 작업에서 집계 시퀀스 표현으로 사용됨.
- 문장 Pair는 함께 묶여 단일 시퀀스로 만듬.
- 두 가지 방법으로 문장을 구별함 :
- 특별 토큰 ([SEP]) 으로 문장들을 분리함.
- 토큰이 문장 \(\mathbb{A}\) 또는 \(\mathbb{B}\) 어디에 속하는지를 나타내도록 모든 토큰에 학습된 임베딩을 추가함.
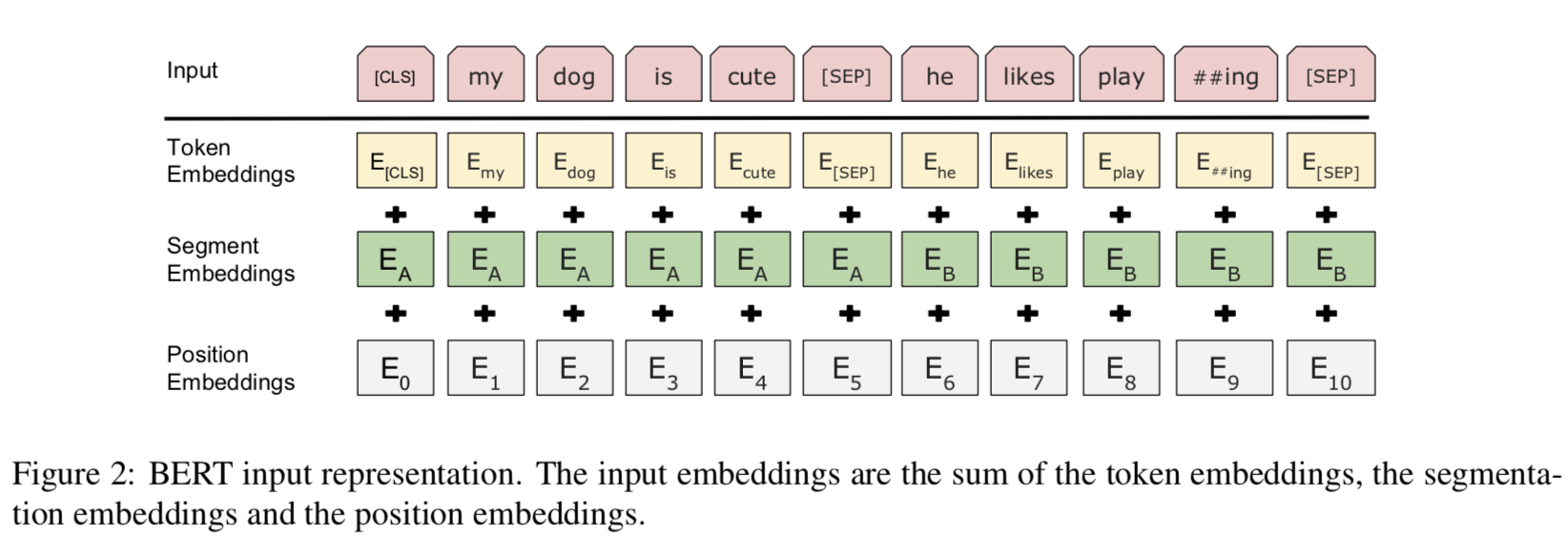
- Figure 1 처럼, 우리는 다음과 같이 나타냄 :
- Input 임베딩 : \(E\)
- 특별 토큰 [CLS]의 최종 Hidden 벡터 : \(C \, ∈ \, \mathbb{R}^{H}\)
- \(i^{th}\) Input 토큰에 대한 최종 Hidden 벡터 : \(T_{i} \, ∈ \, \mathbb{R}^{H}\)
- 토큰이 주어지면, 토큰의 Input 표현은 해당하는 토큰, 세그먼트, 위치 임베딩을 합치면서 구축됨.
- 이 구축의 시각화는 Figure 2에서 볼 수 있음.
3-1. Pre-training BERT
- 우리는 BERT를 Pre-training하기 위해, left-to-right 또는 right-to-left 같은 전통적인 언어모델을 사용하지 않음.
- 대신, 두 가지 비지도 작업을 사용하여 BERT를 Pre-training함.
- Figure 1의 왼쪽 부분에 제시되있음.
Task #1: Masked LM (MLM)
- 직관적으로, 심층 양방향 모델은 left-to-right 또는 left-to-right & right-to-left의 얕은 연결 (Shallow Concatenation) 보다 더 강력하다고 믿는 것이 합리적임.
- 안타깝게도, 표준 조건부 언어 모델은 양방향 훈련이 각 단어가 간접적으로 "See Itself" 할 수 있게 하며, 모델이 다중 계층의 Context에서 타겟 단어를 평범하게 예측할 수 있기 때문에, left-to-right 또는 right-to-left로만 훈련될 수 있음.
심층 양방향 표현을 훈련하기 위해서, 우리는 무작위로 일부 Input 토큰을 마스크 씌우고, 가려진 토큰을 예측함.
- 우리는 이 절차를 "Masked LM" (MLM) 이라고 하지만, 종종 일부 문헌에서는 \(Cloze\) 작업이라고도 말함.
- 이 경우, 마스크 씌워진 토큰들에 해당하는 최종 Hidden 벡터들은 표준 LM 처럼 어휘집합을 통해 Output Softmax에 공급됨.
이를 통해 양방향 Pre-training된 모델을 얻을 수는 있지만, [MASK] 토큰이 Fine-tuning 동안 나타나지 않기 때문에 Pre-training과 Fine-tuning 사이의 불일치가 발생함.
- 이를 완화하기 위해, 우리는 항상 "Masked" 단어들을 실제 [MASK] 토큰으로 대체하지는 않음.
- 훈련 데이터 생성기는 예측을 수행하기 위해 무작위로 토큰 위치의 15%를 선택함.
- \(i\) 번째 토큰이 선택되면, \(i\) 번째 토큰을 다음으로 대체함 :
- 80%의 경우, [MASK] 토큰
- 10%의 경우, 무작위 토큰
- 10%의 경우, 바뀌지 않은 \(i\) 번째 토큰
- 그 다음, \(T_{i}\) 는 교차 엔트로피 손실을 이용하여 원래 토큰을 예측하기 위해 사용될 것임.
Task #2: Next Sentence Prediction (NSP)
- QA, NLI 같은 중요 다운스트림 작업들은 언어 모델링에 의해 직접 포착되지 않는 두 개의 문장들 사이의 \(Relationship\) 에 대한 이해가 바탕으로 깔림.
- 문장 간 관계를 이해하는 모델을 훈련하기 위해, 어떤 단일 언어적 말뭉치에서 평범하게 생성될 수 있는 이진화된 \(Next\) \(Sentence\) \(Prediction\) 에 대해 Pre-training함.
- 문장의 관계를 이해하는 모델을 학습 시키기 위해서, 우리는 모든 단일 언어 코퍼스에서 평범하게 생성될 수 있는 이진화된 다음 문장 예측 작업에 대해 pre-training함.
- 구체적으로, 각 Pre-training 예시에 대해 문장 A와 B를 선택할 때, 50%의 경우 B가 A 다음에 나오는 실제 다음 문장 (IsNext의 레이블을 가진) 이며, 50%의 경우 말뭉치에서 무작위 문장이 됨 (NotNext의 레이블을 가진).
- Figure 1에서 본 것처럼, \(C\) 는 다음 문장 예측에 사용됨.
- 이전 작업에서, BERT가 최종 작업 모델 파라미터로 초기화한 모든 파라미터를 옮긴 문장 임베딩만이 다운스트림 작업에 전이됨.
Pre-training data
- Pre-training 절차는 언어 모델 Pre-training에 관한 기존 문헌을 주로 따름.
- 긴 연속 시퀀스를 추출하기 위해서는 Billion Word Benchmark 같은 문장이 뒤죽박죽인 말뭉치 보다 문서 수준 말뭉치를 사용하는 것이 중요함.
3-2. Fine-tuning BERT
- 트랜스포머의 Self-attention 메커니즘이 BERT가 단일 텍스트 또는 텍스트 Pair를 포함하는지 여부와 적절한 Input과 Output을 교환하여 많은 다운스트림 작업을 모델링할 수 있도록 해주기 때문에 Fine-tuning은 간단함.
- 텍스트 Pair와 관련있는 어플리케이션의 경우, 일반적인 패턴은 양방향 교차 Attention을 적용하기 전에 텍스트 Pair를 독립적으로 Encode하는 것임.
- 대신, BERT는 Self-attention을 이용하여 연결된 텍스트 Pair를 Encoding하는 것은 두 문장 사이의 양방향 교차 Attention을 효과적으로 포함하기 때문에, 이러한 두 가지 단계를 통합하기 위해 Self-attention 메커니즘을 사용함.
- 각 작업 마다, 우리는 간단히 Task-specific한 Input과 Output을 BERT와 연결하고, 모든 파라미터들을 End-to-End로 Fine-tuning함.
Input
- Pre-training한 문장 A와 B는 아래 것들과 유사함 :
- Paraphrasing의 문장 Pair
- Entailment의 Hypothesis-Premise Pair
- QA의 Question-Passage Pair
- 텍스트 분류 또는 시퀀스 태깅의 축약된 (Degenerate) 텍스트-∅ Pair
Output
- 토큰 표현은 QA 또는 시퀀스 태깅 같은 토큰-수준 작업에 대한 Output 계층에 공급됨.
- [CLS] 표현은 감성 분석, Entailment 같은 분류에 대한 Output 계층에 공급됨.
4. Experiments
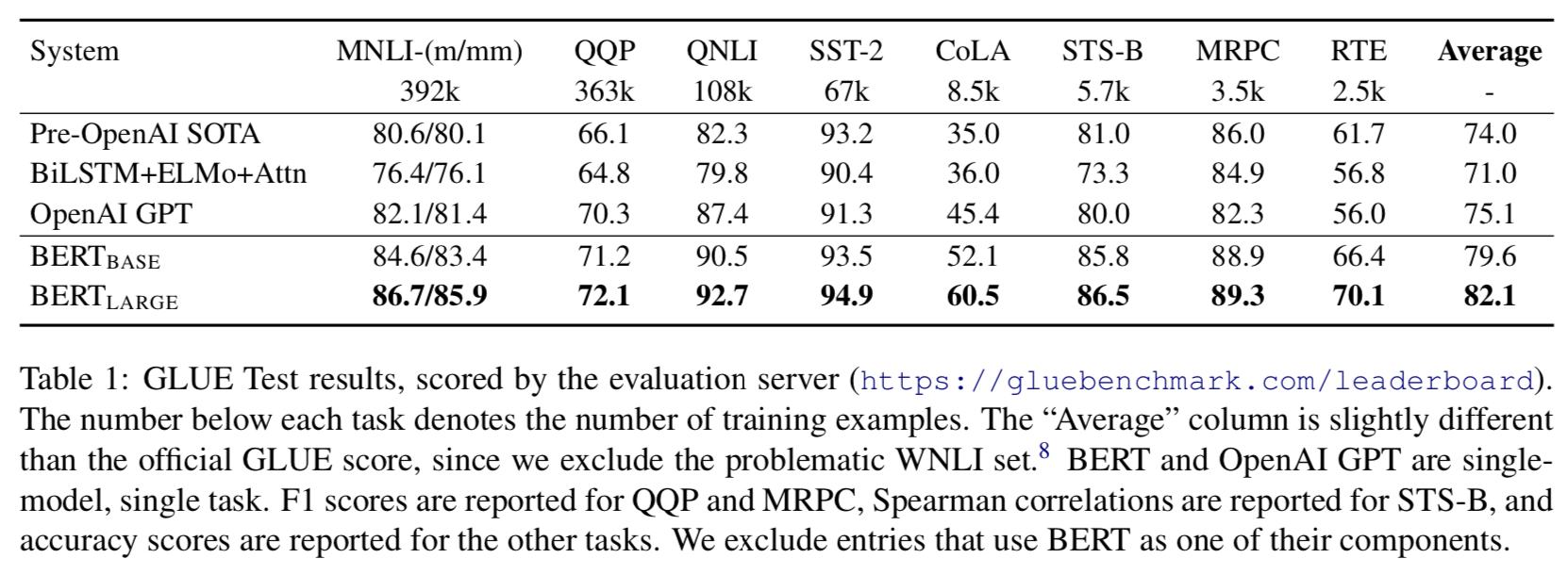
4.1 GLUE
- 일반적 언어 이해 평가 (GLUE, General Language Understanding Evaluation) Benchmark는 다양한 자연어 이해 작업의 집합임.
- GLUE로 Fine-tuning 하기 위해, 우리는 Section 3에서 설명한 것처럼 Input 시퀀스 (단일 문장 또는 문장 Pair의 경우) 를 표현하고, 첫 번째 Input 토큰 ([CLS])해 해당하는 최종 Hidden 벡터 \(C \, ∈ \, \mathbb{R}^{H}\) 를 집계 표현으로 사용함.
- Fine-tuning동안 도입된 새로운 파라미터는 분류 계층 가중치 \(W \, ∈ \, \mathbb{R}^{K\times H}\) 이며, \(K\) 는 레이블 갯수를 의미함.
- 우리는 \(C\) 와 \(W\) 를 이용하여 표준 분류 손실 (즉, log(softmax(\(CW^{T}\)))) 을 계산함.
- \(BERT_{LARGE}\) 의 경우, 작은 데이터셋에서 Fine-tuning이 가끔씩 불안정한 것을 발견했음.
- Table 1 에 결과들이 나와있음.
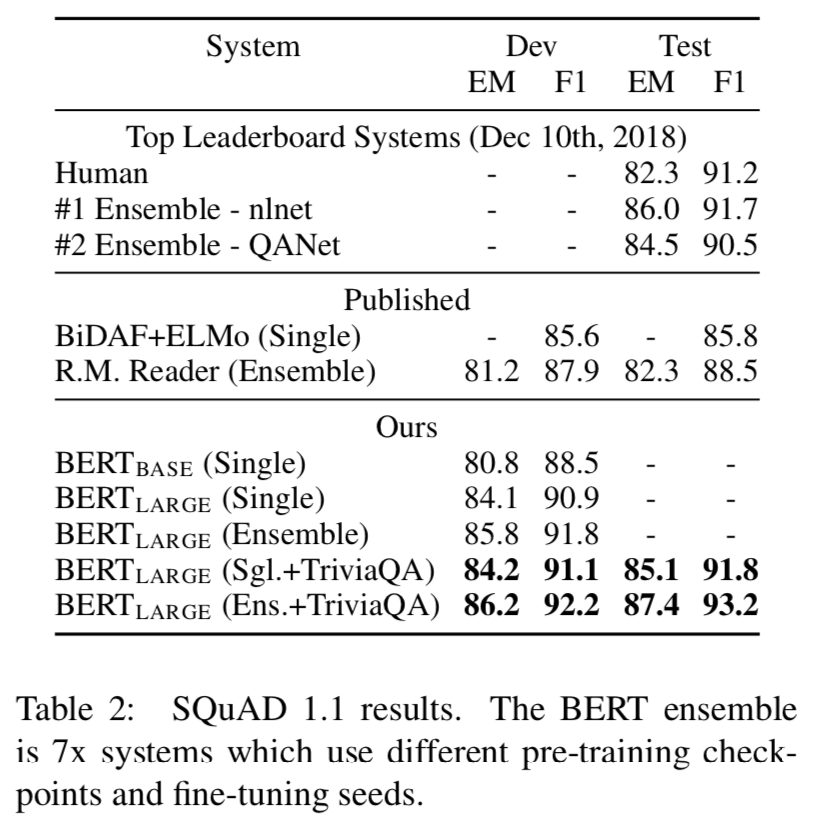
4.2 SQuAD v1.1
- SQuAD v1.1 (The Stanford Question Answering Dataset) 은 QA Pair 집합임.
- 결과는 Table 2를 통해 보여줌.
4.3 SQuAD v2.0
- SQuAD 2.0 과제는 제공된 Paragraph에 짧은 답이 존재하지 않을 가능성을 허용하여, 1.1 문제 정의를 확장하여 문제를 더 현실화시킴.
- Table 3를 통해 결과를 보여줌.

4.4. SWAG
- SWAG (The Situations With Adversarial Generations) 데이터셋은 기초 상식 추론을 평가하는 문장 Pair Completion 예제를 포함함.
- 문장이 주어지면, 4 가지 선택 중 가장 그럴듯한 Continuation을 선택하는 것이 과제임.
- Table 4는 이 결과를 보여줌.

5. Ablation Studies
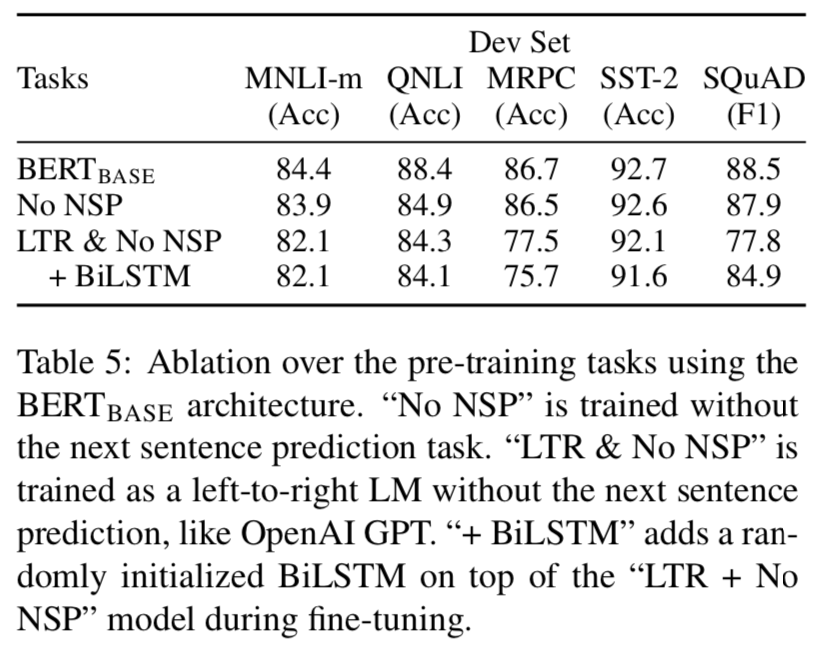
5.1 Effect of Pre-training Tasks
- 정확히 동일한 Pre-training 데이터, Fine-tuning Scheme, \(BERT_{BASE}\) 의 하이퍼파라미터를 사용하여, 두 개의 Pre-training Objectives를 평가함으로써 BERT의 심층 양방향의 중요성을 증명함.
No NSP
- "Next Setence Prediction" 과제 없이 "Masked LM" (MLM) 만을 사용하여 훈련된 양방향 모델.
LTR & No NSP
- MLM이 아닌 표준 LTR (Left-To-Right) 를 사용하여 훈련된 left-context-only 모델.
- Left-only 제약은 제거하면 다운스트림 성능이 저하되는 Pre-training & Fine-tuning 불일치를 유발하기 때문에 Fine-tuning에도 적용됐음.
- 추가적으로, 이 모델은 NSP 작업 없이 Pre-training됨.
- 별도로 LTR & RTL 모델을 훈련시키고, 두 모델을 연결하여 각 토큰을 표현하는 것도 가능하다는 것을 인식함.
- 하지만, 다음과 같은 문제점이 있음 :
- 단일 양방향 모델을 사용하는 것보다 두 배이상 비용이 생김.
- RTL 모델이 질문에 대한 답을 조건화 (Condition) 할 수 없기 때문에 QA와 같은 작업에 대해 직관적이지 않음.
- 이것은 모든 계층에서 왼쪽과 오른쪽 Context를 모두 사용할 수 있기 때문에, 심층 양방향 모델보다 강력하지 않음.
5.2 Effect of Model Size
- Table 6에 GLUE 과제에 대한 결과를 보여줌.

- \(BERT_{BASE}\) 는 110M 파라미터를 포함함.
- \(BERT_{LARGE}\) 는 340M 파라미터를 포함함.
- 우리는 이 모델이 Pre-training을 충분히 받은 경우, 극단적인 모델 크기로 확장하는 것이 또한 매우 작은 규모의 작업에서 큰 개선으로 이어진다는 것을 설득력 있게 입증하는 첫 번째 작업이라고 믿음.
5.3 Feature-based Approach with BERT
- Pre-training된 모델에서 고정된 Features를 추출하는 Feature-based 접근법도 이점을 가짐.
- 트랜스포머 Encoder 아키텍처로 모든 작업을 쉽게 표현할 수는 없기 때문에, Task-specific 모델 아키텍처를 추가해야함.
- 훈련 데이터의 값비싼 표현을 Pre-compute한 다음 이 표현 위에 더 싼 모델로 여러 가지 실험을 실행할 수 있는 중요한 계산적 이점이 있음.
- Table 7을 통해 결과를 보여줌.

6. Conclusion
- 최근에는 언어 모델을 이용한 전이 학습 (Tranfer Learning) 이 좋은 개선을 보여주고, 비지도 Pre-training이 많은 언어 이해 시스템의 필수적인 부분인 것을 보여줬음.
- 특히, 이러한 결과들은 심지어 심층 단일 아키텍처에서 적은 자원으로 과제를 수행할 수 있는 이점을 제공함.
- 우리의 중요 공헌은 심층 양방향 아키텍처에 이러한 연구 결과를 더욱 일반화하여, 동일한 Pre-training 모델이 광범위한 NLP 과제를 성공적으로 처리할 수 있게 하는 것임.
Appendix
A Additional Details for BERT
A.1 Illustration of the Pre-training Tasks
Maksed Lm & the Masking Procedure
- 레이블이 없는 문장 "my dog is hairy" 가 있다고 가정해보겠음.
- 그리고 무작위로 마스크를 씌우는 과정을 진행하면서, 우리는 4번째 토큰 ("hairy") 를 선택했고, 마스킹 과정을 다음과 같이 추가 설명함.
- 80%의 경우 : "my dog is hairy" -> "my dog is [MASK]" 처럼 [MASK] 토큰으로 대체함.
- 10%의 경우 : "my dog is hairy" -> "my dog is apple" 처럼 무작위 다른 단어로 대체함.
- 10%의 경우 : "my dog is hairy" -> "my dog is hairy" 처럼 실제 단어를 변경하지 않음.
- 3번째 경우의 목적은 실제 관측된 단어쪽으로 표현을 Bias 하기 위함임.
이 절차의 이점은 트랜스포머 Encoder가 어떤 단어를 예측할 지 또는 어떤 단어가 무작위 단어로 대체될 지 알지 못한다는 것임.
- 그래서, 이는 모든 Input 토큰의 Distributed Contextual 표현을 유지하도록 강요받음.
- 추가적으로, 무작위 대체가 모든 토큰에서 1.5% (즉, 10% ~ 15%) 에서만 발생하기 때문에, 모델 언어 이해 능력에 해를 끼칠 것으로 보이지는 않음.
- 표준 언어 모델 훈련과 비교했을 때, MLM은 각 배치에서 토큰의 15% 만을 예측하며, 이는 모델을 수렴시키기 위해 더 많은 Pre-training 단계가 필요할 수 있다는 것을 시사함.
Next Sentence Prediction
- NSP 작업은 예제는 아래와 같음 :
- Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
- Label = IsNext
- Input = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
- Label = Not next
A.2 Pre-training Procedure
- 각 훈련 Input 시퀀수 생성하기 위해서, 우리는 말뭉치에서 두 개 텍스트 조각 (Spans) 을 Sampling함.
- 비록 이 텍스트 조각들이 보통 단일 문장보다 훨씬 더 길지만 (또한, 더 짧을 수도 있음), "Sentences" 라고 언급하는 것임.
- 첫 번째 문장은 A 임베딩을 받고, 두 번째 문장은 B 임베딩을 받음.
- 50%의 경우, B는 A 다음에 나오는 실제 다음 문장이 됨.
- 나머지 50%의 경우, 무작위 문장이 됨.
- 이러한 과정은 "Next Sentence Prediction" 작업에서 수행됨.
- LM 마스킹은 WordPiece 토큰화 후에 적용되며, 이는 15%의 균일한 마스킹 비율을 적용하고, 부분 Word Pieces에는 특별하게 고려할 사항은 없음.
- 활성 함수는 ReLU가 아닌 GeLU를 사용함.

'Paper > NLP' 카테고리의 다른 글
| Attention Is All You Need (0) | 2020.02.16 |
|---|---|
| Supervised Paragraph Vector: Distributed Representations (0) | 2019.04.04 |