
티스토리 뷰
반응형
논문
Abstract
- 우수한 시퀀스 Transduction 모델은 Encoder & Decoder를 가진 복잡한 RNN 또는 CNN을 기반으로 구성됨.
- 최고 성능 모델은 또한 어텐션 (Attention) 메커니즘을 통해 Encoder & Decoder를 연결함.
- 우리는 트랜스포머 (Transformer) 라는 새롭고 간단한 네트워크 아키텍처를 제시함.
- 이는 Recurrence & Convolution 을 완전히 제외하고, 어텐션 메커니즘만을 기반으로 함.
- 두 가지 기계 번역 연구 실험에서, 이러한 모델들이 훨씬 병렬적이고 훈련 시간이 더 적게 소요되는 반면, 성능이 우수하다는 것을 보여줌.
1. Introduction
- RNN (Recurrent Neural Network), LSTM (Long Short-Term Memory), GRU는 특히 언어 모델링 & 기계 번역 같은 시퀀스 모델링 & Transduction 문제에서 굉장히 좋은 접근법으로 구축됐음.
- 그 이후에도, Recurrent 언어 모델과 Encoder-Decoder에 대한 수많은 노력들이 있었음.
- 일반적으로, Recurrent 모델은 Input & Output 시퀀스의 심볼 위치에 따라 계산을 고려함.
- 계산 시간 단계에 맞춰 위치를 할당하면, 모델이 이전 Hidden State \(h_{t-1}\) 의 함수 & 위치 \(t\) 에 대한 Input으로써, Hidden State \(h_{t}\) 시퀀스를 생성함.
- 이러한 본질적인 순차적인 특성은 훈련 예시 내에서 병렬화를 배제시킴.
- 이는 메모리 제약이 예제 간 Batching을 제한하기 때문에, 더 긴 시퀀스 길이에서 치명적임.
- 최근 연구에서는 Factorization 기법 & 조건부 연산을 통해 계산 효율성에서 상당한 개선을 달성했음.
- 하지만, 순차적 계산에 대한 근본적인 제한은 여전히 남아있음.
어텐션 메커니즘은 Input 또는 Output 시퀀스 거리에 관계없이 Dependency를 모델링할 수 있도록, 다양한 태스크에서 시퀀스 모델링과 Transduction 모델의 필수적인 부분이 되었음.
- 그러나, 어텐션 메커니즘은 몇 가지 경우를 제외하고는 RNN과 함께 사용됨.
- 이 연구에서 우리는 트랜스포머를 제시함.
- Recurrence를 피하는 대신, 어텐션 메커니즘에만 전적으로 의존하는 모델 아키텍처임.
- 어텐션 메커니즘은 Input & Output 사이의 Global Dependency를 끌어내기 위한 것임.
- 트랜스포머는 보다 더 많은 병렬화를 가능하게 하며, 8개의 P100 GPU에서 12시간 정도 훈련을 받은 후, 번역 품질에서 최신 수행 능력에 도달할 수 있음.
2. Background
- 순차적 계산량을 감소시키는 목표는 또한 Extended Neural GPU, ByteNet, ConvS2S의 기초를 형성함.
- 이 네트워크들 전부 모든 Input & Output 위치에 대한 Hidden 표현을 병렬로 계산하고, CNN을 기본 구축 블록으로 사용함.
- 이러한 모델들에서, 임의의 두 Input 또는 Output 위치 신호를 연관시킬 때 필요한 연산 횟수는 위치 간 거리에서 증가함.
- ConvS2S는 선형적으로, ByteNet은 대수적으로 (Logarithmically) 증가함.
- 이는 거리 위치 간 Dependency 학습을 어렵게 만듬.
- 트랜스포머에서는, Averaging Attention-weighted 위치로 인한 효과적인 해결 (Resolution) 감소 비용이지만, 멀티-헤드 어텐션으로 대응한 효과로 인해 일정한 연산 수로 감소됨.
- 종종 인트라-어텐션 (Intra-attention) 으로도 부르는 셀프-어텐션 (Self-attention) 은 시퀀스 표현을 계산하기 위해 단일 시퀀스의 서로 다른 위치와 관련된 어텐션 메커니즘임.
- 셀프-어텐션은 다음을 포함하는 다양한 태스크에서 성공적으로 사용되어 왔음.
- Reading Comprehension
- Abstractive Summarization
- Textual Entailment
- Learning Task-independent Sentence Representation
- 셀프-어텐션은 다음을 포함하는 다양한 태스크에서 성공적으로 사용되어 왔음.
- 엔드-투-엔드 메모리 네트워크는 Sequence-aligned Recurrence 대신, Recurrent 어텐션 메커니즘을 기반으로 하며, 단순-언어 QA (Question Answering) 와 언어 모델링 태스크에 잘 작동하는 것을 보임.
- 그러나, 우리가 알고 있는 내에서는, 트랜스포머가 Sequence-aligned RNN 또는 CNN 없이, Input & Output 표현을 계산하기 위해 전적으로 셀프-어텐션만을 사용한 최초 Transduction 모델임.
3. Model Architecture
- 가장 경쟁할 만한 시퀀스 Transduction 모델은 Encoder-Decoder 구조를 가지고 있음.
- 여기서, Encoder는 Input 심볼 시퀀스 표현 \((x_{1}, ..., x_{n})\) 을 연속적인 시퀀스 표현 \(\mathbf{z} = (z_{1}, ..., z_{n})\) 으로 매핑함.
- \(\mathbf{z}\) 가 주어진 다음, Decoder는 Output 심볼 시퀀스 \((y_{1}, ..., y_{m})\) 중 원소 하나를 생성함.
- 각 단계 마다, 모델은 Auto-regressive하며, 다음 Input이 생성될 때, 이전에 생성된 심볼을 추가 Input으로 사용함.
- 트랜스포머는 각각 Figure 1의 왼쪽과 오른쪽에 나타난 Encoder & Decoder의 완전 연결 계층이 겹겹이 쌓인 셀프-어텐션과 Point-wise를 사용하여 이 종합적인 아키텍처를 따름.
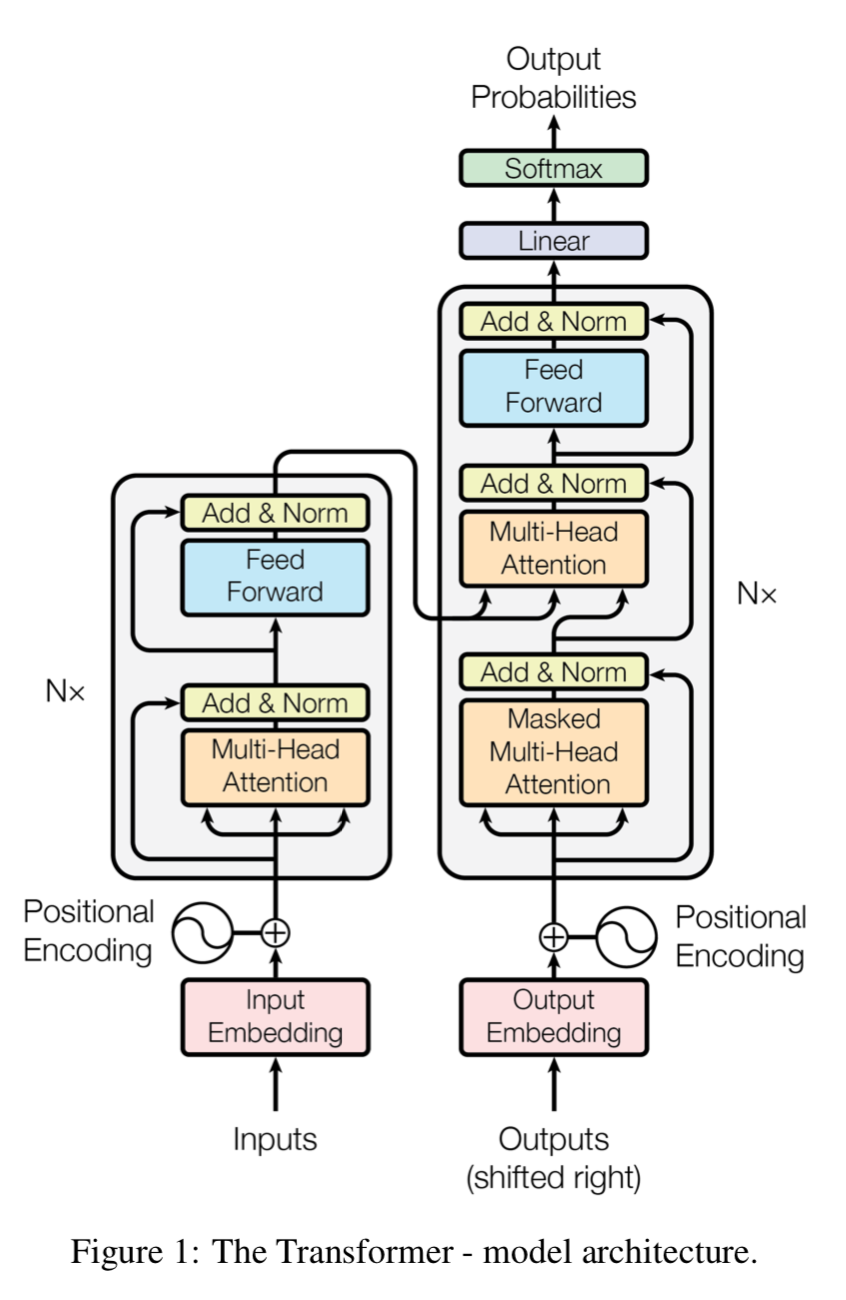
3.1 Encoder & Decoder Stacks
Encoder :
- \(N\) = 6 인 동일한 계층 스택으로 구성됨.
- 각 계층은 두 개의 하위-계층을 가짐.
- 1. 멀티-헤드 셀프-어텐션 (Multi-head Self-attention) 메커니즘
- 2. 간단한, Position-wise 완전 연결 피드-포워드 네트워크 (Fully Connected Feed-forward Network)
- 우리는 두 하위-계층 근처에서 Residual Connection을 사용하고, 이어서 계층 정규화 (Normalization) 를 수행함.
- 즉, 각 하위-계층 Output은 \(LayerNorm(x + Sublayer(x))\) 가 됨.
- \(Sublayer(x)\) 는 하위-계층 자체에서 수행되는 함수임.
- 이러한 Residual Connection을 가능하게 하기 위해, 모델의 모든 하위-계층 뿐만 아니라 임베딩 계층도 \(d_{model}\) = 512 차원의 Output을 생성함.
- 각 계층은 두 개의 하위-계층을 가짐.
Decoder :
- Encoder와 똑같이 동일한 6개의 계층 스택으로 구성됨.
- 각 Encoder 계층의 두 하위-계층 외에도, Decoder는 3번째 Sub-계층을 추가로 삽입함.
- 이는 Encoder 스택의 Output을 가지고 멀티-헤드 어텐션을 수행함.
- Encoder와 유사하게, 우리는 하위-계층 근처에서 Residual Connection을 사용하고, 이어서 계층 정규화를 수행함.
- 또한, 우리는 위치들이 다음 위치에 관여하는 것을 방지하기 위해 Decoder 스택의 셀프-어텐션 하위-계층을 수정함.
- 각 Encoder 계층의 두 하위-계층 외에도, Decoder는 3번째 Sub-계층을 추가로 삽입함.
- Output 임베딩이 한 위치로 Offset 된다는 사실과 결합된 이 Masking은 위치 \(i\) 에 대한 예측이 \(i\) 보다 작은 위치에서 알려진 Output에만 의존할 수 있음을 보장함.
3.2 Attention
- 어텐션 함수는 쿼리와 키-값 Pair 집합을 Output으로 매핑하여 설명될 수 있음.
- 쿼리 (Query), 키 (Key), 값 (Value), Output은 모두 벡터임.
- Output은 값을 가중합하여 계산됨.
- 각 값에 할당된 가중치는 이에 해당하는 키와 쿼리의 호환성 함수에 의해 계산됨.
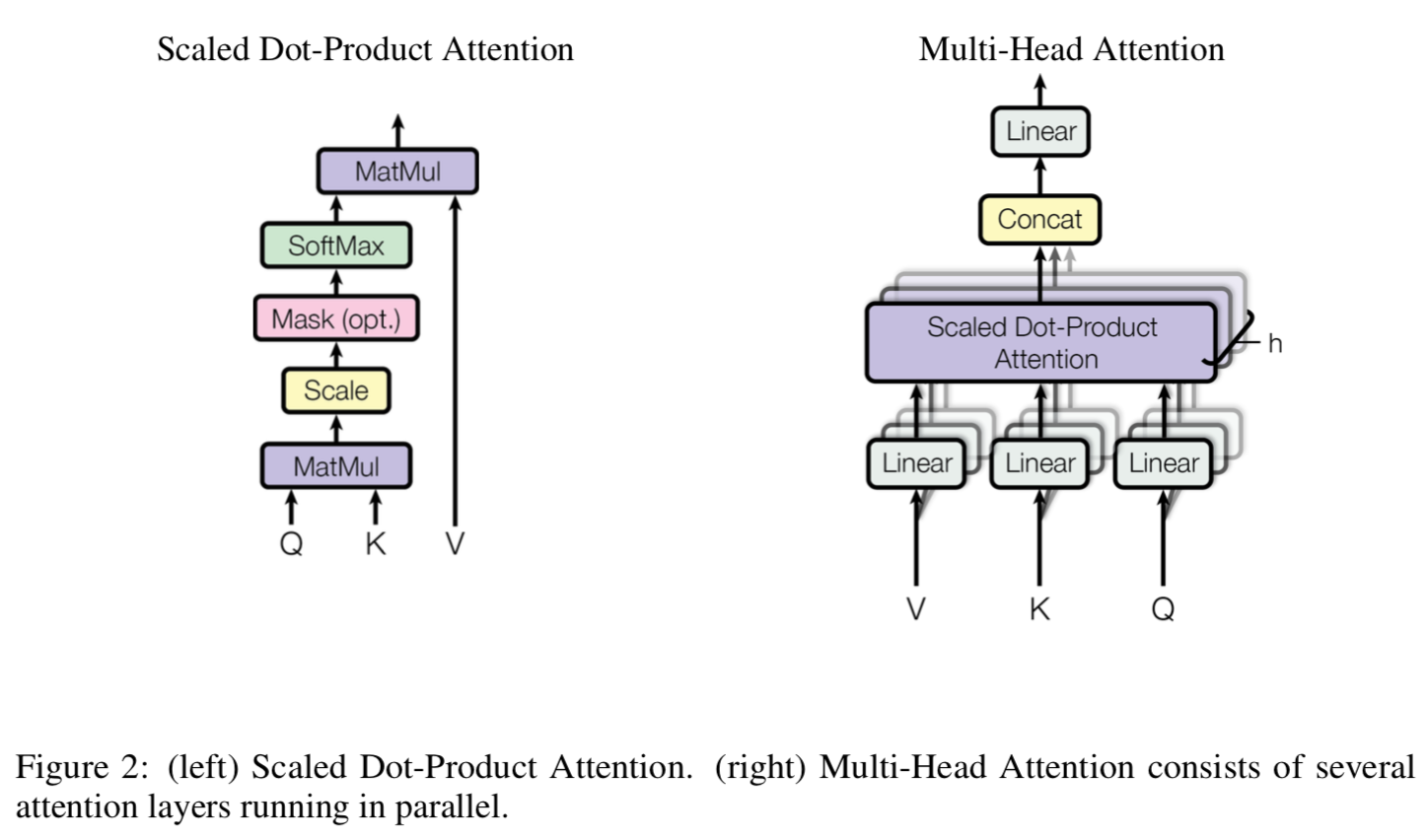
3.2.1 Scaled Dot-Product Attention
- 우리의 특별한 어텐션을 "Scaled Dot-Product Attention" 이라고 부름.
- Input은 \(d_{k}\) 차원의 키, \(d_{v}\) 차원의 값, 그리고 쿼리로 구성되어 있음.
- 우리는 모든 키와 쿼리의 Dot Products를 계산하고, 모두 \(\sqrt{d_{k}}\) 로 나눈 다음, 값의 가중치를 얻기 위해 소프트맥스 함수를 적용함.
- 실제로, 우리는 쿼리 집합의 어텐션 함수를 동시에 계산하고, 이를 함께 행렬 \(Q\) 로 묶음.
- 키와 값도 마찬가지로 행렬 \(K\) & \(V\) 로 묶음.
- Output 행렬을 다음과 같이 계산함 :
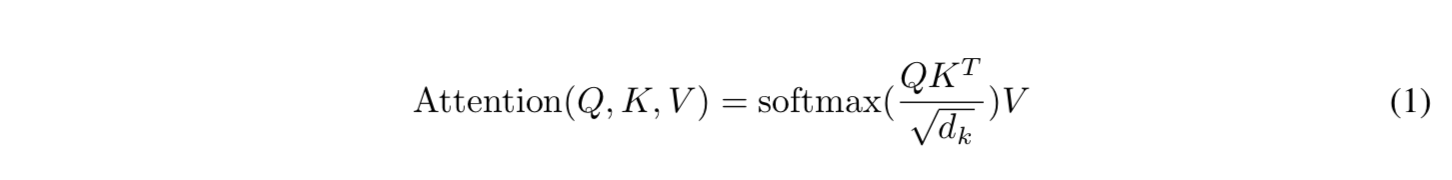
- 가장 흔하게 사용되는 두 가지 어텐션 함수는 Additive 어텐션과 Dot-product (Multiplicative) 어텐션임.
- Dot-product 어텐션은 Scaling Factor \(1 \over{d_{k}}\) 를 제외하면, 우리 알고리즘과 동일함.
- Additive 어텐션은 단일 Hidden 계층을 가진 피드-포워드 네트워크를 사용하여 호환성 함수를 계산함.
- 이 두 가지는 이론적 복잡성 면에서는 유사함.
- 하지만, Dot-product 어텐션이 매우 최적화된 행렬 Multiplication 코드를 사용하여 구현될 수 있기 때문에, 실제로 훨씬 더 빠르고 공간-효율적임.
- 작은 \(d_{k}\) 값의 경우, 두 가지 메커니즘이 유사하게 수행됨.
- 하지만, Additive 어텐션이 더 큰 \(d_{k}\) 값에 대한 Scaling 없이 더 나은 성능을 냄.
- 큰 \(d_{k}\) 값의 경우, Dot-product가 규모가 더 커져서 소프트맥스 함수를 극도로 작은 Gradients 영역으로 밀어넣는다고 의심함.
- 이러한 영향에 대응하기 위해, \(1 \over{d_{k}}\) 로 Dot-products를 Scaling함.
3.2.2 Multi-Head Attention
- \(d_{model}\)-차원의 키, 값, 쿼리와 단일 어텐션 함수를 수행하는 대신, 우리는 다음과 같이 수행하는 것이 이점이 된다는 것을 발견했음.
- 각각 차원 \(d_{k}\), \(d_{k}\), \(d_{v}\) 에 대해 학습된 서로 다른 선형 투영 (Projections) 을 이용하여 쿼리, 키, 값을 \(h\) 시간 동안 선형적으로 투영하는 것.
- 이렇게 투영된 모든 쿼리, 키, 값에서, 우리는 어텐션 함수를 병렬로 수행하고, \(d_{v}\)-차원의 Output 값을 산출함.
- 이것들이 연결되고 (Concatenated) 다시 투영되면 최종 값들을 결과로 내주고, 이는 Figure 2에 묘사되어 있음.
- 멀티-헤드 어텐션은 모델이 서로 다른 위치의 서로 다른 표현 Subspaces 정보에 공동으로 관여할 수 있게 해줌.
- 단일 어텐션 헤드를 이용하여, Averaging은 다음을 억제함 :

- 투영은 다음과 같은 파라미터 행렬들을 의미함 :
- \(W^{Q}_{i} \in \mathbb{R}^{d_{model} \, \times \, d_{k}}\)
- \(W^{K}_{i} \in \mathbb{R}^{d_{model} \, \times \, d_{k}}\)
- \(W^{V}_{i} \in \mathbb{R}^{d_{model} \, \times \, d_{v}}\)
- \(W^{O} \in \mathbb{R}^{hd_{v} \, \times \, d_{model}}\)
- 이 연구에서, 우리는 \(h\) = 8인 병렬 어텐션 계층 또는 헤드를 사용함.
- 각 계층들의 경우, 우리는 \(d_{k}\) = \(d_{v}\) = \(d_{model} / h\) = 64 를 사용함.
- 감소된 각 헤드 차원 덕분에, 총 계산 비용은 Full 차원을 가진 단일-헤드 어텐션 비용과 유사함.
3.2.3 Applications of Attention in our Model
- 트랜스포머는 세 가지 방법으로 멀티-헤드 어텐션을 사용함 :
- "Encoder-Decoder Attention" 계층에서, 쿼리는 이전 Decoder 계층에서, 메모리 키와 값은 Encoder Output에서 나옴
- 이러한 점은 Decoder의 모든 위치에서 Input 시퀀스의 모든 위치에 관여할 수 있게 함.
- 일반적으로, 이는 시퀀스-to-시퀀스 모델의 Encoder-Decoder Attention 메커니즘을 흉내내는 것임.
- Encoder는 셀프-어텐션 계층을 포함함.
- 셀프-어텐션 계층에서, 모든 키, 값, 쿼리는 동일한 곳에서 나오며, 이 경우는 Encoder의 이전 계층 Output이 됨.
- Encoder의 각 위치는 이전 계층 Encoder의 모든 위치에 관여할 수 있음.
- 이와 유사하게, Decoder의 셀프-어텐션 계층은 Decoder의 각 위치가 해당 위치를 포함하여 Decoder의 모든 위치에 관여할 수 있게 함.
- 우리는 Auto-regressive 특성을 보존하기 위해, Decoder의 Leftward 정보 흐름을 예방할 필요가 있음.
- 불법적 연결에 해당하는 소프트맥스 Input의 모든 값을 마스킹 (\(-\infty\)로 설정) 하여, Scaling된 Dot-product 어텐션 내부를 구현함.
- Figure 2에 설명되어 있음.
- "Encoder-Decoder Attention" 계층에서, 쿼리는 이전 Decoder 계층에서, 메모리 키와 값은 Encoder Output에서 나옴
3.3 Position-wise Feed-Forward Networks
- 어텐션 하위-계층 외에도, 우리의 Encoder & Decoder의 모든 계층들은 완전 연결 피드-포워드 네트워크를 포함함.
- 이 네트워크는 각 위치에 개별적 & 동일하게 적용됨.
- 또한, 이 네트워크는 중간에 ReLU 활성 함수가 있는 두 개의 선형 변환을 포함 하고 있음.
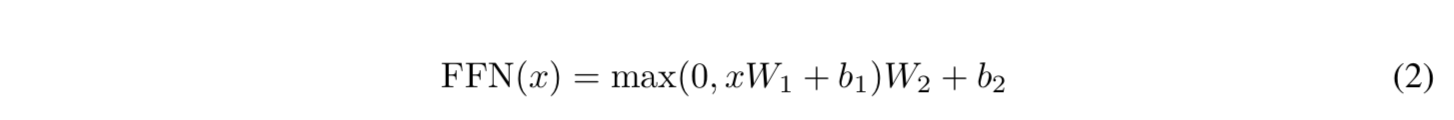
- 선형 변환들이 서로 다른 위치에 걸쳐 동일하게 동작하지만, 층마다 다른 파라미터를 사용함.
- 이를 설명할 수 있는 또 다른 방법은 크기 1의 커널을 가진 두 개의 Convolutions임.
- Input & Output 차원은 \(d_{model}\) = 512 이고, 내부-계층은 \(d_{f \, f}\) = 2048 차원을 가짐.
3.4 Embeddings and Softmax
- 다른 시퀀스 Transduction 모델과 유사하게, 우리는 Input & Output 토큰을 \(d_{model}\) 차원의 벡터로 변환시키기 위해, 학습된 임베딩을 사용함.
- 또한, 우리는 Decoder Output을 예측된 다음-토큰 확률로 변환하기 위해, 학습된 선형 변환 & 소프트맥스 함수를 사용함.
- 모델에서, 우리는 Pre-softmax 선형 변환과 두 개의 임베딩 계층 사이에서 동일한 가중치 행렬을 공유함.
- 임베딩 계층에서, 우리는 \(\sqrt{d_{model}}\) 로 그러한 가중치들을 곱함.
3.5 Positional Encoding
- 우리 모델이 Recurrence & Convolution도 없기 때문에, 모델이 시퀀스 순서를 활용하도록 만들기 위해서 시퀀스 토큰의 상대적 또는 절대적 위치에 대한 정보를 주입해야 함.
- 이를 위해, Encoder & Decoder 스택 바닥의 Input 임베딩에 "Positional Encodings" 를 추가함.
- Positional Encodings는 동일한 \(d_{model}\) 차원의 임베딩을 가지므로, 이 둘을 합산할 수 있음.
- 이 연구에서, 우리는 서로 다른 빈발도의 Sine & Cosine 함수를 사용함 :
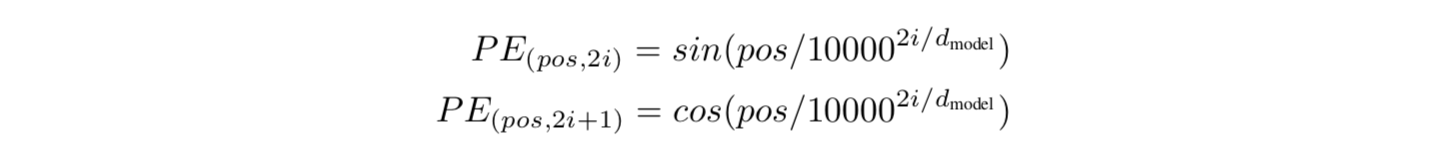
- 파라미터 설명 :
- \(pos\) : 위치
- \(i\) : 차원
- 즉, Positional Encoding의 각 차원은 Sine 곡선에 해당함.
- 파장은 2\(\pi\) ~ 10000 \(\times 2\pi\) 까지의 기하학적 진행으로 형성됨.
- 우리는 모델이 상대적인 위치에 따라 쉽게 학습에 관여할 수 있다고 가정했기 때문에 이 함수를 선택했음.
- 이 가정을 할 수 있었던 이유는 어떤 고정 오프셋 \(k\) 이든, \(PE_{pos+k}\) 가 \(PE_{pos}\)의 선형 함수로 표현될 수 있기 때문임.
- 또한, 우리는 학습된 Positional 임베딩을 사용하여 실험했고, 두 가지 버전이 거의 동일한 결과들을 생성한다는 사실을 발견했음.
- 우리는 Sine 곡선 버전을 선택했음.
- 그 이유는 모델이 훈련 동안 마주치는 것보다 더 긴 시퀀스 길이로 추론할 수 있기 때문임.
4. Why Self-Attention
- 셀프-어텐션 계층의 다양한 측면을 RNN & CNN과 비교함.
- 우리는 세 가지 희망사항을 고려함.
- 하나는 계층 별 총 계산 복잡성임.
- 또 다른 하나는 필요한 최소 순차 연산 수로 측정했을 때, 병렬화할 수 있는 계산량임.
- 세 번째는 네트워크의 Long-range Dependencies 사이의 경로 길이임.
- Long-range Dependencies 학습은 많은 시퀀스 Tranduction 태스크의 핵심 과제임.
- 그러한 Dependencies 학습 능력에 영향을 미치는 핵심 요인 중 하나는 Forward & Backward 시그널 경로 길이임.
- 이 경로들이 짧을 수록, Long-range Dependencies를 학습하기 쉬움.
- 따라서, 서로 다른 계층 타입으로 구성된 네트워크의 어떤 두 개의 Input & Output 위치 사이의 최대 경로 길이를 비교함.
- Table 1과 같이, 셀프-어텐션 계층은 순차적으로 실행된 상수 개의 작업으로 모든 위치를 연결하는 반면, RNN 계층은 \(O(n)\) 의 순차적 연산을 필요로 함.

- 계산 복잡도 관점에서, 셀프-어텐션 계층은 시퀀스 길이 \(n\) 이 표현 차원 \(d\) 보다 작을 때, RNN 계층보다 더 빠름.
- 이는 Word-piece & Byte-pair 같은 기계 번역에서 최신 모델에 의해 사용되는 문장 표현에 가장 흔히 해당됨.
- 매우 긴 시퀀스와 관련된 태스크에 대한 계산 성능을 향상시키기 위해, 셀프-어텐션은 각 Output 위치를 중심으로 Input 시퀀스에서 \(r\) 크기 이웃만을 고려하는 것으로 제한될 수 있음.
- 이는 최대 경로 길이를 \(O(n/r)\) 로 증가시킬 수 있음.
7. Conclusion
- 우리는 전적으로 어텐션만을 기반으로 한, 첫 번째 시퀀스 Tranduction 모델인 트랜스포머를 제시했음.
- 이는 Encoder-Decoder 아키텍처에서 가장 흔하게 사용되는 Recurrent 계층을 멀티-헤드 셀프-어텐션으로 대체함.
- 번역 태스크의 경우, 트랜스포머는 Recurrent 또는 Convolutional 계층 기반 아키텍처보다 더 빠르게 훈련될 수 있음.
반응형
'Paper > NLP' 카테고리의 다른 글
| BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (0) | 2019.08.10 |
|---|---|
| Supervised Paragraph Vector: Distributed Representations (0) | 2019.04.04 |
댓글