
티스토리 뷰
논문
Abstract
- 부스팅 트리 (Boosting Tree) 는 매우 효과적이고 널리 사용되는 머신러닝 방법임.
- 이 논문에서 우리는 XGBoost 라는 확장 가능한 (Scalable) End-to-End 트리 부스팅 시스템을 설명함.
- 우리는 Sparse한 데이터에 대한 새로운 희소성 인식 알고리즘 (Sparsity-Aware Algorithm) 과 근사적인 트리 학습 (Approximate Tree Learning) 을 위한 Weighted Quantile Sketch 를 제시함.
- 더 중요한 것은, 우리가 Scalable한 트리 부스팅 시스템을 구축하기 위해 캐시 (Cache) 액세스 패턴, 데이터 Compression 및 Sharding 에 대한 Insight를 제공함.
- 이러한 통찰을 결합함으로써, XGBoost는 기존 시스템보다 훨씬 더 적은 자원을 사용하여, 수십억 개 이상의 예제로 Scale함.
Keywords
- Large-scale Machine Learning
1. Introduction
- 머신 러닝과 데이터-기반 접근법들은 많은 영역에서 매우 중요해졌음.
- 스팸 분류기, 광고 시스템, 이상 현상 탐지 시스템 등 성공적인 어플리케이션으로 이끈 두 가지 중요한 요인 (Factors) 이 있음 :
- 복잡한 데이터 종속성을 포착하는 효율적인 (통계적인) 모델 사용.
- 대규모 Dataset에서 관심 모델을 학습하는 Scalable한 학습 시스템.
- 실제로 사용되는 머신 러닝 방법 중, 그래디언트 부스팅 트리 (GBT, Gradient Boosting Tree) 는 많은 어플리케이션에서 빛을 발하는 효과적인 기법 중 하나임.
이 논문에서는, 부스팅 트리에 대해 Scalable한 머신 러닝 시스템인 XGBoost를 설명함.
- 이 시스템은 오픈 소스 패키지이기 때문에 자유롭게 사용 가능함.
- Kaggle에서 주최하는 대회에서 대부분의 Winning Solution이 XGBooost를 사용했으며, Top-10 내 Winning 팀은 모두 XGBoost를 사용했음.
- 심지어, 우승 팀이 구성한 앙상블 방법은 잘 학습된 XGBoost보다 약간 더 좋은 성능을 발휘한다는 것이 기록됐음.
- 이러한 결과들을 통해 XGBooost가 광범위한 문제들에서 최신 결과를 제공한다는 것이 증명됨.
- 예제 문제들의 종류는 다음과 같음 :
- 가게 판매량 예측 (Store Sales Prediction).
- 고 에너지 물리 사건 분류 (High Energy Physics Event Classification).
- 웹 텍스트 분류 (Web Text Classification).
- 고객 행동 예측 (Customer Behavior Prediction).
- ... 등등
XGBoost의 가장 중요한 성공 요인은 모든 시나리오에서 Scalable하다는 것임.
- 단일 머신을 이용하여 기존 솔루션 보다 10배 이상 더 빠르게 실행되며, 분산되거나 제한된 메모리 상황에서도 수십억 개 이상의 예제들로 Scalable함.
- XGBoost의 Scalability는 일부 중요한 시스템과 알고리즘적인 최적화 덕분임.
- 이러한 혁신은 다음과 같은 내용을 포함함 :
- 새로운 트리 학습 알고리즘은 Sparse한 데이터를 다루기 위한 것임.
- 이론적으로 입증된 Weighted Quantile Sketch 절차는 근사 트리 학습에서 인스턴스 가중치를 다룰 수 있게 만들어줌.
- 병렬 및 분산 컴퓨팅은 학습 속도를 향상시켜 모델 탐색을 가속화함.
- 더 중요한 것은 XGBoost가 Out-of-Core 계산을 사용하고, 데이터 과학자들이 데스크탑에서 수억 개의 예시를 처리할 수 있도록 만들어줌.
- 마지막으로, 이러한 기법들을 결합하고, 최소한의 클러스터 자원을 사용하여 더 큰 데이터로 Scalable하는 End-to-End 시스템을 만드는 것은 굉장히 흥미로운 일임.
기존에도 일부 병렬적 부스팅 트리에 대한 연구들이 있지만, Out-of-Core 계산, 캐시 & Sparsity 인식 학습 방향은 연구되지 않았음.
- 더 중요한 것은, 이러한 모든 측면들을 결합한 End-to-End 시스템은 실제 사용 사례들에 대해 새로운 솔루션을 제공함.
- 이는 데이터 과학자 뿐만 아니라 연구원이 강력한 부스팅 트리 알고리즘을 응용하여 구축할 수 있게 해줌.
- 이러한 주요 공헌 이외에도, Regularized 학습 목적함수를 제시하고, 완성도를 위해 포함할 Column Sub-Sampling 을 지원하여, 추가적으로 개선함.
2. Tree Boosting in a Nutshell
2-1. Regularized Learning Objective
- \(n\) 개의 예제 & \(m\) 개의 Features 를 가진 데이터셋 \(D \, = \, \{(\mathbf{x}_{i}, y_{i})\}\) (|\(D\)| \(= \, n, \mathbf{x}_{i} \, ∈ \, \mathbb{R}^{m}, \, y_{i} \, ∈ \, \mathbb{R})\) 이 주어졌다고 해보겠음.
- 트리 앙상블 모델 (Figure 1) 은 Output을 예측하기 위해 \(K\) 개의 Additive 함수를 사용함.


- 파라미터 설명 :
- \(F\) = \(\{f(\mathbf{x}) \, = \, w_{q(\mathbf{x})}\}\) (\(q\) : \(\mathbb{R}^{m}\) -> \(T\), \(w \, ∈ \, \mathbb{R}^{T})\) : 회귀 나무 공간 (CART 라고도 부름)
- \(q\) : 해당하는 잎 인덱스에 예제를 매핑하는 각 트리 구조
- \(T\) : 트리 잎 갯수
- \(f_{k}\) : 독립적인 나무 구조 \(q\) & 잎 가중치 \(w\)
- \(F\) = \(\{f(\mathbf{x}) \, = \, w_{q(\mathbf{x})}\}\) (\(q\) : \(\mathbb{R}^{m}\) -> \(T\), \(w \, ∈ \, \mathbb{R}^{T})\) : 회귀 나무 공간 (CART 라고도 부름)
- 의사 결정 나무 (Decision Tree) 와 달리, 각 회귀 나무는 잎에 연속적인 점수를 가지고 있으며, 우리는 \(i\) 번째 잎의 점수를 나타내기 위해 \(w_{i}\) 를 사용함.
- 주어진 예시에서, 우리는 트리에서 잎을 분류하기 위해 트리 (\(q\) 로 주어진) 의 결정 규칙 (Decision Rule) 을 사용하고, 해당되는 잎 (\(w\) 로 주어진) 에서 점수를 합산하여 최종 예측을 수행함.
- 모델에서 사용된 함수 집합을 학습하기 위해서, 다음과 같은 \(Regularized\) 목적함수를 최소화 해야함 :
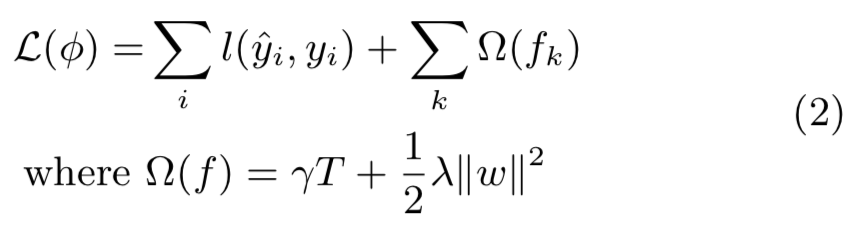
- 파라미터 설명
- \(l\) : 예측값 \(\hat{y}_{i}\) & 타겟값 \(y_{i}\) 사이의 차이를 측정하는 미분 가능한 볼록 (Convex) 손실 함수
- \(\Omega\) : 모델 복잡도에 패널티를 부과 (즉, 회귀 나무 함수들)
- 추가 Regularization Term은 Over-fitting을 피하기 위해 최종 학습된 가중치들을 Smooth 하게 만듬.
2-2. Gradient Tree Boosting
- 수식 (2) 의 트리 앙상블 모델은 함수들을 파라미터로 가지며, 유클리드 공간에서 전통적인 최적화 방법들을 사용하여 최적화할 수 없음.
- 대신, 이 모델은 추가적인 방식으로 훈련됨.
- 형식적으로, \(t\) 번째 반복에서 \(i\) 인스턴스 예측값이 \(\hat{y}^{(t)}_{i}\) 라고 하겠음.
- 우리는 다음과 같은 목적함수를 최소화 하기 위해 \(f_{i}\) 를 추가해야 함.

- 일반적인 환경으로 목적함수를 빠르게 최적화 하기 위해, Second Order Taylor Expansion 을 사용하여 근사적으로 계산함.

- 파라미터 설명
- \(g_{i} \, = \, \partial_{\hat{y}^{(t-1)}} \, l(y_{i}, \, \hat{y}^{(t-1)})\) : 손실 함수의 1차 (First Order) Gradient 통계량
- \(h_{i} \, = \, \partial^{2}_{\hat{y}^{(t-1)}} \, l(y_{i}, \, \hat{y}^{(t-1)})\) : 손실 함수의 2차 (Second Order) Gradient 통계량
- 우리는 상수 Terms 제거해서 다음과 같이 단계 \(t\) 에서 단순화된 목적함수를 얻을 수 있음 :
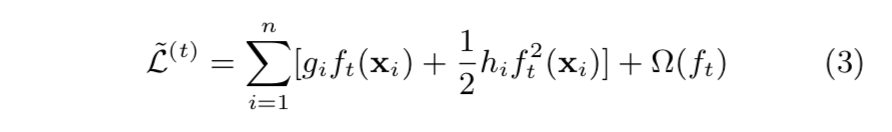
- 잎 \(j\) 의 인스턴스 집합을 \(I_{j} \, = \, \{i \, | \, q(\mathbf{x}_{i}) \, = \, j\}\) 로 정의하겠음.
- 우리는 Regularization Term \(\Omega\) 를 확장하여, 수식 (3) 을 다음과 같이 다시 작성할 수 있음 :

- 고정된 구조 (Structure) \(q(\mathbf{x})\) 의 경우, 다음과 같이 잎 \(j\) 의 최적의 가중치 \(w^{*}_{j}\) 를 계산할 수 있음 :

- 그리고, 다음과 같이 해당하는 최적의 목적함수를 계산할 수 있음 :

- 수식 (6) 트리 구조 \(q\) 의 품질을 측정하기 위해 함수에 점수를 매기는 역할로 사용될 수 있음.
- 이 점수는 보다 광범위한 목적 함수를 위해 도출된다는 점을 제외하면, 의사결정 나무를 평가하기 위한 불순도 점수와 같음.
- Figure 2는 이 점수가 어떻게 계산되는지 설명해줌.

- 수식 (6) 과 같이 해당하는 최적의 목표 함수 값을 계산할 수 있음.
- 보통, 가능한 모든 트리 구조 \(q\) 를 나열하는 것은 불가능함.
- 대신, 한 잎에서 시작하여 반복적으로 트리를 가지 (Branch) 에 추가하는 탐욕 알고리즘이 사용됨.
- \(I_{L}\) & \(I_{R}\) 이 분할 후의 왼쪽 & 오른쪽 인스턴스 집합이라고 가정하겠음.
- \(I \, = \, I_{L} \, \cup \, I_{R}\) 로 놓은 다음, 분할 후의 손실 감소는 다음과 같이 주어짐 :
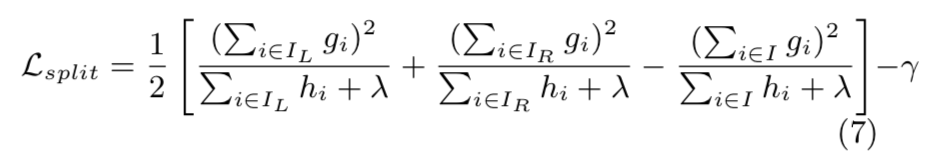
- 이 식은 보통 분할 후보들을 추정하는데 사용됨.
2-3. Shrinkage and Column Subsampling
- Section 2.1에서 언급한 Regularized 목적함수 외에도, 추가적으로 Over-fitting을 예방하는 두 가지 기법들이 사용됨.
(1) Shrinkage
- 부스팅 트리의 각 단계 이후 마다 새롭게 추가된 가중치를 요인 \(\eta\) 로 Scaling 함.
- Stochastic 최적화의 Learning Rate와 유사하게, 각 개별 트리의 영향도를 감소시키고, 모델을 향상시키기 위해 미래 트리 공간을 남겨놓음.
(2) Column (Feature) Subsampling
- 이 기법은 Random Forest에서 흔하게 사용되지만, 이전 부스팅 트리에서는 적용되지 않았음.
- 유저 피드백에 따르면, 전통적인 Row Subsampling보다 Over-fitting을 더 잘 예방해준다고 함.
- 이 기법을 사용하면 병렬 알고리즘 계산 속도를 가속화함.
3. Split Finding Algorithms
3-1. Basic Exact Greedy Algorithm
트리 학습의 핵심적인 문제 중 하나는 수식 (7) 이 나타내는 것처럼, 가장 좋은 분할을 찾는 것임.
- 그러기 위해서, 분할 탐색 알고리즘은 모든 Features에서 가능한 모든 분할들을 열거함.
- 이를 \(EGA, \, Exact \, Greedy \, Algorithm\) 이라고 함.
- 기존 단일 머신 부스팅 트리의 대부분에서는 이 알고리즘을 지원하며, Algorithm 1에서 설명함.

- 연속적인 Feature에 대해 가능한 모든 분할들을 열거해야함.
- 효율적으로 수행하기 위해, Feature 값에 따라 데이터를 정렬해야 하고, 수식 (7) 의 구조 점수에 대한 Gradient 통계량을 축적하기 위해 정렬된 순서에 따라 데이터를 찾아감.
3-2. Approximate Algorithm
- EGA는 가능한 모든 분할 지점들을 탐욕적으로 열거하기 때문에 굉장히 강력함.
- 하지만 메모리에 데이터가 완전히 적합되지 못할 때, 효율적으로 수행하는 것은 불가능함.
- 이와 동일한 문제는 분산된 환경에서도 발생하게 됨.
- 이 두 가지 상황에서 효율적인 GBT를 지원하기 위해, 근사 알고리즘 (AA, Approximate Algorithm) 을 사용해야 함.
- 부스팅 트리의 AA 프레임워크는 Algorithm 2에 주어짐.

- 요약하자면, 이 알고리즘은 먼저 Feature 분포의 Percentiles에 따라 후보 분할 지점을 제시함.
- 그런 다음, 연속적인 Feature를 이러한 후보 지점으로 나뉜 Bucket에 매핑하고 통계량을 집계한 다음, 집계된 통계량을 바탕으로 만들어진 Proposal 중 가장 좋은 솔루션을 찾음.
Proposal이 주어진 시기에 따라, 두 가지 다른 버전으로 알고리즘이 나뉨.
- Global Variant :
- 초기 트리 구성 단계에서 모든 후보 분할들을 제시하고, 모든 Levels에서 분할 찾기를 수행할 때 동일한 Proposals를 사용함.
- Local Variant :
- 매번 분할이 진행된 후에 다시 제시함.
- Proposal 단계 수 : Global < Local
- 후보 분할 지점 갯수 : Global > Local
- 매번 분할이 진행된 후에 후보 분할 지점이 개선 (Refine) 되지 않기 때문임.
- Local Proposal은 분할이 진행된 후에 후보를 개선하고, 잠재적으로 더 깊은 트리에 더 적합할 수 있음.
- Figure 3을 통해 다른 알고리즘과의 비교를 보여줌.

3-3. Weighted Quantile Sketch
AA의 중요한 단계 중 하나는 후보 분할 지점을 제시하는 것임.
- 보통 Feature Percentiles는 후보들이 데이터에 균등하게 분산되도록 하기 위해 사용됨.
- \(k\) 번째 Feature 값과 각 훈련 인스턴스의 2차 Gradient 통계량을 나타내는 다중 집합 \(D_{k} \, = \, \{(x_{1k}, h_{1}), (x_{2k},h_{2}), \cdots, (x_{nk}, h_{n})\}\) 이 이 있다고 해보겠음.
- 우리는 랭크 함수 \(r_{k} \, : \, \mathbb{R} \to [0, +\infty)\)를 다음과 같이 정의할 수 있음 :

- 이는 Feature 값 \(k\) 가 \(z\) 보다 작은 인스턴스의 비율을 나타냄.
- 목표는 후보 분할 지점 \(\{s_{k1}, s_{k2}, \cdots, s_{kl}\}\) 을 찾는 것임 :

- \(\epsilon\) : 근사치 인자 (Appoximation Factor)
- 직관적으로, 이는 대략 1 / \(\epsilon\) 의 후보 지점이 있다는 것을 의미함.
- 각 데이터 지점은 \(h_{i}\) 에 의해 가중치됨.
- \(h_{i}\) 가 왜 가중치를 나타내는지 보기 위해, 다음과 같이 수식 (3) 을 다시 작성할 수 있음 :

- 이는 레이블 \(g_{i}\) / \(h_{i}\) 과 가중치 \(h_{i}\) 를 이용한 정확히 가중치가 적용된 제곱 손실을 의미함.
- 대규모 데이터셋에서, 이 기준을 만족하는 후보 분할을 찾는 것은 쉽지 않음.
- 모든 인스턴스가 동일한 가중치를 가질 때, Quantile Sketch 이라 부르는 기존 알고리즘은 이 문제를 해결할 수 있음.
- 그러나, 가중치가 적용된 데이터셋에 대한 Quantile Sketch 는 존재하지 않음.
- 따라서, 기존에 존재하는 부스팅 트리 알고리즘 대부분은 실패할 확률이 있거나 이론적 보장이 없는 데이터의 무작위 Subset에 의존함.
이러한 문제를 해결하기 위해, Distributed Weighted Qunatile Sketch 알고리즘을 제시함.
- 이 알고리즘은 \(Provable \, Theoretical \, Guarantee\) 를 가지고 가중치가 적용된 데이터를 다룰 수 있음.
- 일반적인 아이디어는 각 작업에서 일정한 정확도 수준을 유지할 수 있도록 보장된 상태에서, \(Merge) & \(Prune) 작업을 지원하는 데이터 구조를 제시하는 것임.
3-4. Sparsity-aware Split Finding
- 실제 많은 문제들에서는 Input \(\mathbf{x}\) 가 Sparse 한 것은 흔한 일임.
- Sparsity를 유발하는 여러 가지 가능성이 있음 :
- 데이터 내 결측치의 존재 유무
- 통계량에서 빈번한 0 엔트리
- One-hot Encoding 같은 Feature Engineering Artifacts
데이터 내 Sparsity 패턴을 인식하는 알고리즘을 만드는 것은 중요한 일임.
- 그러기 위해, 우리는 Figure 4 처럼 각 트리 노드 마다 Default Direction을 추가하는 것을 제시함.
- Sparse 행렬 \(\mathbf{x}\) 에서 값이 누락되었을 경우, 인스턴스는 Default Direction으로 분류를 수행함.

- 최적의 Default Direction은 데이터에서 학습되며, Algorithm 3에서 설명함.

- 핵심적으로 개선한 것은 결측되지 않은 엔트리 \(I_{k}\) 만 방문하는 것임.
- 제시된 알고리즘에서는 존재하지 않는 값을 결측치로 처리하고, 결측치를 다루는 가장 좋은 Direction을 학습함.
- 우리가 알고 있는 한도 내에서, 기존 트리 학습 알고리즘 대부분은 Dense한 데이터에만 최적화 되거나, 범주형 (Categorical) Encoding 같은 제한된 경우들을 다루는 구체적인 절차들이 필요함.
- XGBoost는 모든 Sparsity 패턴을 통합된 방식으로 다룸.
- Figure 5는 Sparsity 인식 알고리즘과 Naive한 구현 알고리즘을 비교함.

4. System Design
4-1. Column Block for Parallel Learning
트리 학습 중 시간을 가장 많이 소비하는 부분은 순서가 정렬된 데이터를 얻는 것임.
- 정렬 비용을 감소시키기 위해서, \(Block\) 이라는 인-메모리 (In-memory) 단위로 데이터를 저장하는 것을 제시함.
- 각 블록 내 데이터는 CSC (CompreSsed Column) 형식으로 저장되며, 각 Column은 이에 해당하는 Feature 값으로 정렬됨.
- Input 데이터의 레이아웃은 훈련 전에 한 번만 계산하면 되고, 나중에 반복해서 재사용할 수 있음.
- EGA에서, 우리는 단일 블록에 데이터셋 전체를 저장하고, Pre-sorted된 엔트리에 선형적으로 탐색하여 분할 탐색 알고리즘을 실행함.
- 우리는 모든 잎들을 집단적으로 분할 조사를 수행하고, 블록을 한 번 탐색하면 모든 잎 가지에서 분할 후보들의 통계량이 수집될 것임.
- Figure 6은 데이터셋을 블록-기반 형식으로 어떻게 변형하는지, 블록 구조를 사용하여 최적 분할을 어떻게 찾는 지를 보여줌.
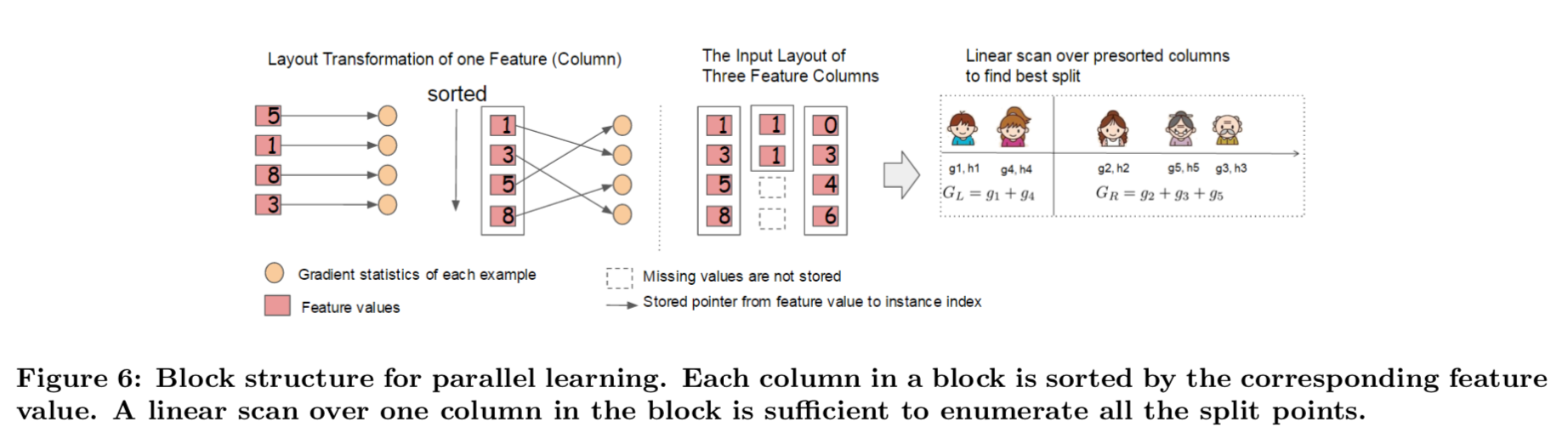
블록 구조는 근사 알고리즘을 사용할 때도 도움을 줌.
- 각 블록들이 데이터셋 Row의 Subset에 해당하는, 다수의 블록들은 이러한 경우에 사용될 수 있음.
- 서로 다른 블록들은 여러 기계들에 분산되거나, Out-of-Core 환경의 디스크에 저장될 수 있음.
- 정렬된 구조를 사용하여, Quantile 탐색 단계는 정렬된 Column에 따라 \(Linear Scan\) 이 됨.
- 이는 각 가지에서 후보가 빈번하게 생성되는 Local Proposal에서 특히 가치가 있음.
각 Column에 대한 통계량을 수집하는 것은 병렬화 (\(Parallelized\)) 될 수 있으며, 이는 분할 탐지에 대해 병렬적인 알고리즘을 제공함.
- 중요한 것은, Column 블록 구조가 Column Subsampling도 지원함.
4-2. Cache-aware Access
- 제시된 블록 구조가 분할 탐지의 계산 복잡도를 최적화하는 데 도움이 되지만, 이 새로운 알고리즘은 이러한 값들이 Feature 순서로 접근되기 때문에 Row 인덱스별 Gradient 통계량의 간접적인 Fetches를 필요로 함.
- 이는 불연속적 메모리 접근 방식임.
- Naive한 분할 열거 구현은 누적과 불연속적 메모리 Fetch 작업 사이의 즉각적인 Read / Write 종속성을 도입함 (Figure 8).
- 이는 Gradient 통계량이 CPU 캐시에 적합되지 않고 캐시 미스가 발생할 때, 분할 탐지를 느리게 만듬.
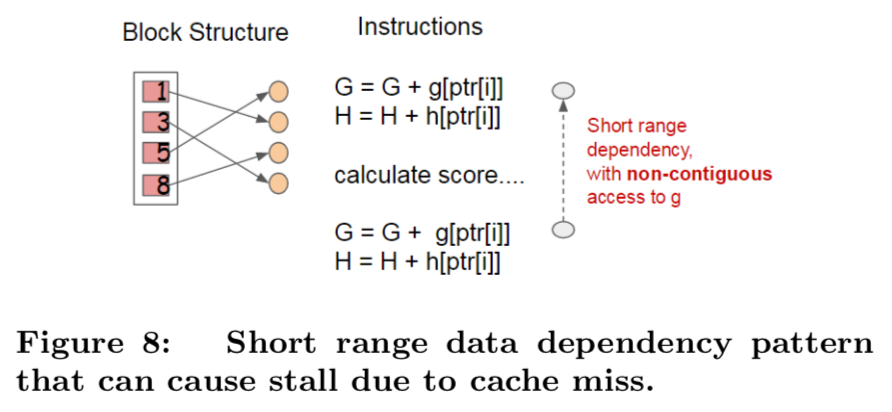
EAG의 경우에서, 캐시-인식 Prefetching 알고리즘을 사용하여 이 문제를 완화할 수 있음.
- 구체적으로, 각 스레드에 내부 버퍼를 할당하고, Gradient 통계량을 버퍼에 Fetch한 다음, Mini-batch 방식으로 통계량 축적을 수행함.
- 이 Prefetching 방식은 직접적인 Read / Write 종속성을 더 긴 종속성으로 변경하고, Row 수가 클 때 실행시간 오버헤드를 감소시켜줌.
- Figure 7은 캐시-인식과 비 캐시-인식 알고리즘 비교를 보여줌.

AA의 경우에서, 정확한 블록 크기를 선택하여 문제를 해결함.
- 블록 크기는 Gradient 통계량의 캐시 저장 비용을 반영하기 때문에 블록에 포함된 예시의 최대 갯수로 블록 크기를 정의함.
- 블록 크기가 지나치게 작다면, 각 스레드의 Wordload가 작아지고, 비효율적인 병렬화가 발생함.
- 블록 크기가 과하게 크다면, Gradient 통계량이 CPU 캐시에 적합되지 않기 때문에, 캐시 미스를 야기함.
- 좋은 블록 크기를 선택하려면 이 두 가지 요인을 적절히 균형있게 맞춰야 하며, Figure 9에서 결과를 보여줌.

4-3. Blocks for Out-of-core Computation
- 우리 시스템 목표 중 하나는 Scalable한 학습을 달성하기 위해, 기계 자원을 충분히 활용하는 것임.
- 프로세서와 메모리 외에도, 디스크 공간을 활용해 메인 메모리에 적합되지 않은 데이터를 다루는 것은 중요함.
- 이러한 Out-of-Core 계산을 수행하기 위해, 데이터를 다중 블록에 나누고, 각 블록을 디스크에 저장함.
- 계산 중에는 메인 메모리 버퍼로 블록을 Pre-fetch 하는 독립적인 스레드를 사용하는 것이 중요하므로, 디스크 Reading과 동시에 계산이 이루어질 수 있음.
- 그러나 디스크 Reading이 계산 시간 대부분을 차지하기 때문에, 문제를 완전히 해결하지는 못함.
- 여기서는 디스크 IO의 처리량을 증가시키고, 오버헤드를 감소시키는 것이 중요함.
- 그래서 우리는 두 가지 기법을 사용할 것임 :
Block Compression
- 블록이 Columns에 의해 압축 (Compressed) 되고, 메인 메모리에 적재됐을 때, 독립 스레드에 의해 Fly 에서 압축해제 (Decompressed) 됨.
- 이는 압축해제의 일부 계산 비용을 디스크 Reading 비용과 교환할 수 있게 해줌.
- 우리는 Feature 값을 압축하기 위해 범용 압축 알고리즘을 사용함.
Block Sharding
- 두 번째 기법은 데이터를 다른 방법으로 여러 개의 디스크에 Sharding 하는 것임.
- Pre-fetcher 스레드는 각 디스크에 할당되고, 데이터를 인-메모리 버퍼에 Fetch함.
- 훈련 스레드는 그런 다음 각 버퍼에서 데이터를 대신 읽어들임.
- 이 기법은 다수의 디스크를 사용할 수 있을 때, 디스크의 Reading 처리량을 높일 수 있음.
7. Conclusion
- 근사 학습에 대해 이론적으로 정의된 Weighted Quantile Sketch와 Sparse한 데이터를 다루는 것에 대한 새로운 Sparsity 인식 알고리즘을 제시했음.
- 연구를 통해 캐시 접근 패턴, 데이터 Compression & Sharding은 부스팅 트리에 대해 Scalable한 End-to-End 시스템을 구축하는 필수적인 요소들이라는 것을 보여줌.
- 이러한 것들은 다른 머신 러닝 시스템에서도 적용이 가능함.
- 이러한 Insights를 결합함으로써, XGBoost는 최소한의 자원을 사용하여 실제 Scale 문제들을 해결할 수 있음.