
티스토리 뷰
반응형
Abstract
- 비선형 Feature Transformation 을 이용한 일반화된 선형 모델은 Sparse Input을 이용하여 대규모 회귀 (Regression) 와 분류 문제에 널리 사용됨.
- Cross-Product Feature Transformations을 이용한 Wide 집합을 통한 Feature 상호작용 기억 (Memorization of Interaction) 은 효과적이고 해석가능한 반면, 일반화 (Generalization) 는 더 많은 Feature Engineering 이 필요함.
- 적은 횟수의 Feature Engineering 을 이용하여, Deep Neural Networks은 저차원의 Dense한 임베딩을 통해 일반화 할 수 있음.
- 그러나, 임베딩을 이용한 Deep Neural Networks는 과도하게 일반화 되고, 유저-아이템 상호작용 (Interactions) 이 Sparse하고 High-Rank 일 때, 관련성이 얼마 없는 아이템을 추천해 줄 수 있음.
- 이 논문에서, 우리는 추천 시스템에서 Memorization과 Generalization의 장점을 결합하기 위해 Wide 선형 모델과 Deep Neural Networks이 공동으로 훈련되는 Wide & Deep Learning 을 제시함.
- 우리는 Google Play에서 시스템을 상품화하고 평가하였음.
- 온라인 실험을 통해, Wide & Deep이 wide-only 와 deep-only와 비교하여 app acquisition을 상당히 증가시켰다는 것을 보여줌.
- 우리는 또한, TensorFlow로 구현하여 오픈소스로 내놓았음.
CCS Concepts
- Computing Methodologies -> Machine Leraning
- Neural Networks
- Supervised Learning
- Information Systems -> Recommender Systems
Keywords
- Wide & Deep Learning, Recommender Systems.
1. Introduction
- 추천 시스템은 Input 쿼리가 유저와 문맥 정보의 집합이고, Output은 랭킹 아이템 리스트인, 검색 랭킹 시스템으로 볼 수 있음.
- 주어진 쿼리에서, 추천 작업은 DB에서 관련있는 아이템을 찾은 다음, 클릭이나 구매 같은 특정한 목적을 바탕으로 아이템 등급이 매겨짐.
일반적인 검색 랭킹 문제와 유사하게, 추천 시스템에서의 한 가지 과제는 Memorization과 Generalization 둘 모두를 달성하는 것임.
- Memorization은 내역 데이터에서 사용 가능한 상관관계를 사용하고, 아이템이나 Feature의 동시 빈발도를 학습함으로써 느슨하게 정의될 수 있음.
- 반면에 Generalization은 상관관계의 타동성 (Transitivity) 에 기반을 두고 있으며, 과거에 한 번도 또는 거의 발생하지 않았던 새로운 Feature 조합을 탐색함.
- Memorization 기반 추천은 보통 더 주제적이고 (Topical) 유저가 이미 작업을 수행한 아이템과 직접 관련이 있음.
- Memorization과 비교하여, Generalization은 추천된 아이템의 다양성을 향상시키는 경향이 있음.
- 이 논문에서, 우리는 Google Play 스토어에 대한 앱 추천 문제에 중점을 두지만, 접근법은 일반적인 추천 시스템에 적용 해야함.
- 산업 환경에서의 대규모 온라인 추천과 랭킹 시스템의 경우, 로지스틱 회귀와 같은 일반화된 선형 모델은 간단하고 확장될 수 있으며, 해석 가능하기 때문에 널리 사용됨.
- 이 모델들은 원-핫 인코딩을 이용한 이진화된 (Binarized) Sparse Features에 대해 종종 훈련됨.
- 예를 들어, 이진 (Binary) Feature "user_installed_app=netflix" 는 유저에게 Netflix가 설치되었다면 값 1을 가짐.
- Memorization은 유저가 Netflix를 설치한 다음 Pandora로 표시되면 (whose value is 1 if the user installed Netflix and then is later shown Pandora) 1의 값을 가지는 AND (user_installed_app=netflix, impression_app=pandora) 같은 Sparse Features에 대해 외적 변환 (Cross-Product Transformations) 을 사용하여 효과적으로 달성할 수 있음.
- 이는 Feature Pair의 동시 발생이 Target 레이블과 얼마나 연관성이 있는지를 설명함.
- Generalization은 AND (user_installed_category=video, impression_category=music) 같은 덜 Granular한 Features를 사용하여 추가될 수 있지만, Menual Feature Engineering이 필요한 경우가 자주 있음.
- Cross-Product Transformation의 한 가지 한계점은 훈련 데이터에 없는 쿼리-아이템 Feature Pair를 일반화 (Generalize) 하지 못한다는 것임.
- Factorization Machines, Deep Neural Networks 같은 임베딩 기반 모델은 부담이 덜 한 Feature Engineering을 이용하여 각 쿼리와 아이템 Feature를 저차원의 Dense한 임베딩 벡터로 학습하여 이전에 관찰되지 않은 쿼리-아이템 Feature Pair을 일반화할 수 있음.
- 그러나, 구체적인 선호를 가진 유저 또는 Narrow Appeal을 가진 틈새 아이템 같은 근본적인 (Underlying) 쿼리-아이템 행렬이 Sparse하고 High-Rank일 때, 쿼리 및 아이템에 대한 효과적인 저차원 표현을 학습하는 것은 어려움.
- 그러한 경우에서는 대부분의 쿼리-아이템 Pair 사이에 상호작용 (Interactions) 이 없어야 하지만, Dense 임베딩은 모든 쿼리-아이템 Pair에 대해 0이 아닌 예측을 초래할 것이며, 따라서 지나치게 일반화하여 관련성이 낮은 추천을 할 수 있음.
- 반면에, Cross-Product Feature Transformations를 이용한 선형 모델은 이러한 "예외 규칙 (Exception Rules)"을 훨씬 적은 파라미터를 가지고 기억 (Memorize) 할 수 있음.
- 이 논문에서, 우리는 Figure 1에 보이는 것처럼 신경 네트워크 요소와 선형 모델 요소를 결합 훈련하여 하나의 모델에서 Memorization과 Generalization 모두를 성취하는 Wide & Deep Learning 프레임워크를 소개함.

2. Recommender System Overview
- 앱 추천 시스템의 개요는 Figure 2에서 나타남.

- 다양한 유저와 문맥적 Features를 포함할 수 있는 쿼리는 유저가 앱 스토어를 방문할 때 발생함.
- 추천 시스템은 유저가 클릭 또는 구매 같은 특정한 액션을 수행할 수 있는 앱 리스트 (Impressions 라고도 함) 를 반환함.
- 쿼리와 Impression 과 마찬가지로 이러한 유저 액션들은 학습기의 훈련 데이터로써 로그에 기록됨.
- DB에 100만 개 이상의 앱들이 있기 때문에, 서비스 대기 시간 요구사항 (종종 O(10) 밀리초) 내의 모든 쿼리에 대해 모든 앱을 완전히 기록하는 것은 어려움.
- 따라서, 쿼리를 받기 위한 첫 단계는 검색 \((Retrieval)\) 임.
- 검색 시스템은 다양한 신호들을 사용하여 쿼리와 가장 잘 맞는 아이템 리스트를 반환하는데, 보통 머신 러닝 모델과 사람 정의 규칙의 조합으로 이루어짐.
- 후보 집합을 감소시킨 후에, 랭킹 \((Ranking)\) 시스템은 모든 아이템 점수를 가지고 등급을 매김.
- 점수는 보통 \(P(y|x)\) 로 나타내며, 유저 Features (ex. 국가, 언어, 인구통계), 상황별 (Contextual) Features (ex. 기기, 하루의 시간, 요일) 및 Impression Features (앱 연령, 앱의 과거 통계) 을 포함하여 Feature \(x\) 에 주어진 유저 액션 레이블 \(y\) 의 확률임.
- 이 논문에서, 우리는 Wide & Deep Learning 프레임워크를 사용한 랭킹 모델에 집중함.
3. Wide & Deep Learning
3.1 The Wide Component
- Wide Component는 Figure 1 (왼쪽) 에 설명된 일반화된 선형 모델 수식 \(y = \) \(w^T x + b\) 임.
- \(y\)는 예측물
- \(x = [x_{1}, x_{2}, ..., x_{d}]\) 는 \(d\) Features 벡터
- \(w = [w_{1}, w_{2}, ..., w_{d}]\) 는 모델 파라미터
- \(b\)는 편향 (Bias)
- Feature 집합은 Raw Input Features와 Transformed Features를 포함함.
가장 중요한 Transformations 중 하나는 \(Cross-Product\) \(Transformations\) 이며, 다음과 같이 정의됨 :

- \(c_{ki}\) 는 Boolean 변수이며, \(i\) 번째 Feature가 \(k\) 번째 Transformation \(φ_{k}\) 의 일부이면 1, 그렇지 않으면 0 값을 가짐.
- Binary Features의 경우, Cross-Product Transformation (ex. "AND(gender=female, language=en)") 은 Features 구성 요소(Constituent) ("gender=female" 및 "language=en") 가 모두 1 일 때만 1, 그 이외에는 모두 0 값을 가짐.
- 이는 Binary Features 사이의 상호작용 (Interactions) 을 포착하고, 일반화된 선형 모델에 비선형성을 추가함.
3.2 The Deep Component
- Deep Component는 Figure 1 (오른쪽) 에 보이는 Feed-forward Neural Network임.
- 범주형 (Categorical) Features의 경우, 기존 Inputs는 Feature Strings (ex. "language=en") 임.
- 희소 (Sparse) 하고 고차원인 이러한 Categorical Features는 먼저 저차원적이고 Dense한 실수 벡터로 변환되며, 흔히 임베딩 벡터로 불림.
- 임베딩의 차원은 보통 O (10) ~ O (100) 로 되어 있음.
- 임베딩 벡터들은 처음에 무작위로 초기화된 다음, 모델 훈련 동안 최종 손실 함수를 최소화하기 위해 갱신됨.
- 이러한 저차원이고 Dense한 임베딩 벡터들은 이후에 Forward를 지나 신경망의 은닉층에 입력됨.
- 구체적으로, 각 은닉층은 다음과 같이 계산을 수행함 :

- 각 파라미터 설명
- \(l\) 는 계층 수
- \(f\) 는 활성화 함수이며 종종 ReLUs (Rectified Linear Units)
- \(a^{(l)}\) 는 활성 (Activations)
- \(b^{(l)}\) 는 Bias
- \(W^{(l)}\) 는 \(l\) 번째 계층의 모델 가중치
3.3 Joint Training of Wide & Deep Model
- Wide Component와 Deep Component는 이들의 Output 로그 오즈 (Odds) 가중합인 예측물을 사용하여 조합되고, 이 조합은 공동 훈련을 위해 하나의 공통 로지스틱 손실 함수에 입력됨.
공동 훈련 (Joint Training ) 과 앙상블 (Ensemble ) 사이에는 뚜렷한 차이점이 있음.
- 앙상블은 개별 모델들이 서로 모르는 채로 따로 훈련을 하고, 이들의 예측은 훈련 시간이 아닌 추론 시간에만 결합됨.
- 이와 반대로, 공동 훈련은 훈련 시간에 합계의 가중치뿐만 아니라 Wide & Deep Part를 동시에 고려하여 모든 파라미터들을 동시에 최적화함.
- 마찬가지로, 모델 사이즈에도 시사하는 바가 있음 :
- 앙상블의 경우, 훈련이 상호배제로 수행되기 때문에, 앙상블 작업에서 합리적인 정확도를 달성하기 위해서는 각 개별 모델 크기가 일반적으로 더 커야 함 (ex. 더 많은 Features와 Transformations).
- 반대로, 공동 훈련의 경우, Wide Part는 Full Size Wide 모델보다 적은 수의 Cross-Product Feature Transformations로 Deep Part 약점을 보완하기만 하면 됨.
- Wide & Deep 모델의 공동 훈련은 미니배치 확률적 (Stochastic) 최적화를 사용하여, 모델의 Wide와 Deep 두 Part의 Output의 Gradients를 동시에 역전파 (Backpropagating) 하여 동작함.
- 이 실험에서, 우리는 모델의 각 Part의 Optimizer로 Deep Part는 AdaGrad, Wide Part는 \(L_{1}\) Regularization를 사용하는 FTRL (Follow-The-Regularized-Leader) 알고리즘을 사용했음.
- 결합된 모델은 Figure 1 (중앙) 에서 보여짐.
- 로지스틱 회귀 문제의 경우, 모델은 다음과 같이 예측함 :

- 각 파라미터 설명
- \(Y\) 는 Binary 클래스 레이블
- \(σ(·)\) 는 시그모이드 (Sigmoid) 함수
- \(φ(x)\) 는 초기 Features \(x\) 의 Cross-Product Transformations
- \(b\) 는 Bias Term
- \(w_{wide}\) 는 Wide 모델의 모든 가중치 벡터
- \(w_{deep}\) 은 최종 활성 (Activations) \(a^{(l_{f})}\) 에 적용된 가중치들
4. System Implementation
- 앱 추천 파이프라인 구현은 Figure 3과 같이 3단계로 구성됨 :
- 데이터 생성 (Data Generation)
- 모델 훈련 (Model Training)
- 모델 서빙 (Model Serving)

4.1 Data Generation
- 한 주기 (Period) 내, 유저와 앱 Impression 데이터가 훈련 데이터를 생성하기 위해 사용됨.
- 각 예시는 하나의 Impression과 대응됨.
- 레이블은 앱 획득 \((app\) \(acquisition)\) 임 : Impressed app이 설치되었다면 값 1, 아니면 값 0을 가짐.
- Categorical Feature Strings를 Integer ID로 매핑한 테이블인 어휘 집합 (Vocabularies) 또한 이 스테이지에서 생성됨.
- 시스템은 최소 횟수 이상 발생한 모든 String Features에 대한 ID 공간을 계산함.
- 연속적인 실수값 Features는 Feature 값 \(x\) 을 \(n_{q}\) 분위수 (Quantiles) 로 나뉜 누적 분포 함수 \(P(X ≤ x)\) 에 매핑하여 \([0, 1]\) 사이로 정규화 됨 (Normalized).
- 정규화된 (Normalized) 값은 \(i\) 번째 분위수 (Quantiles) 에서의 \(\frac{i - 1}{n_{q} - 1}\) 이 됨.
- 분위수 경계 (Quantile Boundaries) 는 데이터 생성 (Data Generation) 단계 동안 계산됨.
4.2 Model Training
- 우리가 실험에서 사용했던 모델 구조는 Figure 4에 나타남.

- 훈련하는 동안, Input 계층은 훈련 데이터와 어휘를 입력으로 받으며, 레이블과 함께 Sparse하고 Dense한 Feature를 생성함.
- Wide Component는 Impression 앱과 유저가 설치한 앱의 Cross-Product Transformations으로 구성됨.
- Deep Component의 경우, 32차원 임베딩 벡터는 각 Categorical Feature에 대해 학습됨.
- 우리는 Dense Features를 이용한 모든 임베딩을 이어 붙여서 (Concatenate) 대략 1200 차원의 Dense한 벡터를 내놓음.
- 그런 다음, 연결된 벡터는 3개의 ReLU 계층과 마지막 로지스틱 Output 유닛으로 공급됨.
- Wide & Deep 모델들은 5천억 개 이상의 예제들로 훈련됨.
새로운 훈련 데이터 집합이 도착할 때마다, 모델을 다시 훈련해야 함.
- 그러나, 매번 처음부터 훈련하는 것은 계산적으로 비용이 많이 들고 데이터가 도착하는 것부터 갱신된 모델 제공까지의 시간을 지연시킴.
- 이 과제를 해결하기 위해, 우리는 이전 선형 모델의 가중치와 임베딩을 가지고 새로운 모델을 초기화하는 웜 스타팅 (Warm-Starting) 시스템을 구현했음.
- 모델을 모델 서버에 로드하기 전에, Dry한 상태의 모델로 실행하여 실시간 트래픽을 처리하는 데 문제가 발생하지 않도록 확실히 해야함.
- 우리는 경험적으로 이전 모델의 품질이 온전한 상태인지 검증함.
4.3 Model Serving
- 일단 모델이 훈련되고 검증되면, 모델을 모델 서버에 로드함.
- 각 요청에 대해서, 서버는 앱 검색 시스템과 각 앱에 점수를 매긴 유저 Features로부터 앱 후보 집합을 받음.
- 그런 다음, 앱은 가장 높은 점수부터 가장 낮은 점수까지 등급이 매겨지고, 이 순서로 유저들에게 앱을 보여줌.
- 점수는 Wide & Deep 모델을 대해 Forward 추론 패스 (Inference Pass) 를 실행하여 계산됨.
- 10ms의 순서에 따라 각 요청을 처리하기 위해, 단일 배치 추론 단계에서 모든 후보 앱에 점수를 매기는 대신, 더 작은 배치를 병렬로 실행하여 병렬 멀티스레딩 방식을 사용하여 성능을 최적화했음.
5. Experiment Results
- 실제 추천 시스템에서 Wide & Deep Learning의 효과를 평가하기 위해, 우리는 실시간 실험을 했으며, 두 가지 측면에서 시스템을 평가했음 :
- 앱 획득 (App Acquisitions)
- 서빙 성능 (Serving Performance)
5.1 App Acquisitions
- 3주 동안 A / B Testing 프레임워크에서 실시간 온라인 실험을 수행했음.
- 대조군 (Control) 그룹의 경우, 유저의 1%가 무작위로 선택됐고, 이전 버전의 랭킹 모델이 생성한 추천을 제시하였는데, 이는 Rich한 Cross-Product Feature Transformations를 이용하여 고도로 최적화된 Wide-Only 로지스틱 회귀 모델임.
- 실험군 그룹의 경우, 유저의 1%가 동일한 Features 집합으로 훈련된 Wide & Deep 모델이 생성한 추천을 제시했음.
- Table 1에 보이는 것과 같이, Wide & Deep 모델이 앱 스토어의 메인 랜딩 페이지의 App Acquisition을 대조군 (통계적으로 유의미함) 대비 +3.9% 향상시켰음.

- 온라인 실험 외에도, 우리는 Holdout set offline 에서 AUC (Area Under Receiver Operator Characteristic Curve) 를 보여줌.
- Wide & Deep 은 오프라인 AUC가 약간 높은 반면, 그 영향은 온라인 트래픽에서 더 큼.
- 가능성 있는 한 가지 이유는 오프라인 데이터셋의 Impressions와 레이블은 고정되있는 반면, 온라인 시스템은 Generalization를 Memorization과 혼합하여 새로운 탐색적 추천을 생성할 수 있고, 신규 유저 반응으로부터 학습할 수 있다는 것임.
5.2 Serving Performance
- 우리의 상용 모바일 앱 스토어가 직면한 높은 수준의 트래픽에 높은 처리량과 낮은 대기 시간으로 서비스를 제공하는 것은 어려운 일임.
- 트래픽이 최고점일 때, 우리 추천 서버는 초당 1천만 개 이상의 앱에 점수를 매김.
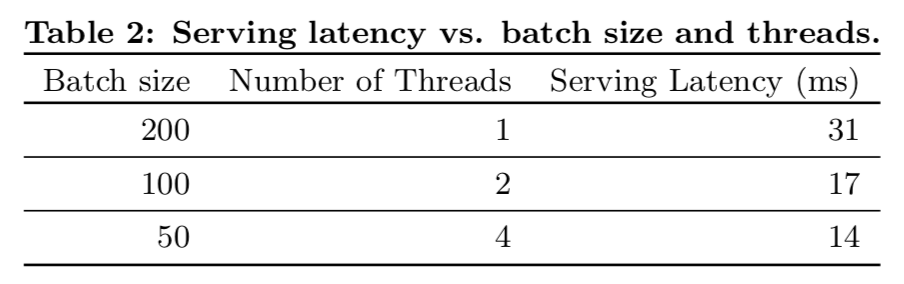
- 단일 스레딩을 이용하여, 단일 배치로 모든 후보에 점수를 매기려면 31ms가 걸림.
- 우리는 멀티스레딩을 구현하고 각 배치를 더 작은 크기로 분할하여 Table 2에 보이는 것처럼 클라이언트 측 지연 시간을 14ms (서비스 오버헤드 포함) 로 크게 줄였음.
6. Related Work
- Dense한 임베딩을 이용한 Deep Neural Networks와 Cross-Product Feature Transformations를 이용한 Wide 선형 모델을 결합하는 아이디어는 Factorization Machines 같은 이전 작업들에서 영감을 받았음.
- Factorization Machines 같은 이전 작업들은 두 개의 저차원 임베딩 벡터 사이에 내적을 수행하여, 두 변수 (Variables) 사이의 상호작용 (Interactions) 을 분해 (Factorizing) 함으로써 선형 모델에 Generalization을 추가함.
- 이 논문에서, 우리는 내적 (Dot Products) 대신 신경망을 통해 임베딩 사이의 비선형 상호작용 (Interactions) 을 많이 학습하여 모델 능력 (Capacity) 을 확장했음.
- 언어 모델에서, RNN과 \(n\)-gram Features를 이용한 최대 엔트로피 모델의 공동 훈련은 Input과 Output 사이에서 가중치를 직접 학습함으로써 RNN 복잡도 (ex. 은닉계층 크기) 를 상당히 감소시키기 위한 방법으로 제시되었음.
- 컴퓨터 비전에서, Deep Residual Learning은 더 깊은 모델에 대한 훈련 어려움을 감소시키고, 하나 또는 그 이상의 계층을 건너뛰는 Shortcut Connections를 이용하여 정확도를 향상시키기 위해 사용되어왔음.
- 또한, 신경망과 그래픽 모델을 결합한 공동 훈련은 이미지에서 사람의 자세를 추측하는 데에도 적용되었음.
- 이 연구에서는, Sparse Input 데이터를 사용한 일반적인 추천과 랭킹 문제에 대해, Sparse Features와 Output Unit 사이의 직접적인 연결을 통해 Feed-forward Neural Network와 선형 모델의 공동 훈련을 탐구했음.
- 추천 시스템 문서에서는, 컨텐츠 정보에 대한 딥러닝과 등급 행렬에 대한 CF를 결합하여 협동 딥러닝을 탐구하였음.
- 또한, 유저의 앱 사용 기록에 대해 CF를 사용했던 AppJoy 같은 모바일 앱 추천 시스템에 대한 이전 작업들이 있음.
- CF 기반 또는 컨텐츠 기반 이전 접근 방식과는 달리, 우리는 앱 추천 시스템의 유저 및 Impression 데이터에 대한 Wide & Deep 모델을 공동으로 훈련함.
7. Conclusion
- Memorization과 Generalization은 추천 시스템에서 모두 중요함.
- Wide 선형 모델은 Cross-Product Feature Transformations를 사용하여 Sparse Feature Interactions를 효과적으로 기억(Memorize) 할 수 있는 반면, Deep Neural Networks는 저차원 임베딩을 통해 이전에 관찰되지 않은 Feature Interactions을 일반화 (Generalize) 할 수 있음.
- 우리는 모델의 두 타입의 강점을 결합한 Wide & Deep Learning 프레임워크를 소개했음.
- 우리는 대규모 상업용 앱스토어인 Google Play의 추천 시스템에서 프레임워크를 제작 및 평가했음.
- 온라인 실험 결과에 따르면, Wide & Deep 모델이 Wide-only와 Deep-only 모델과 비교하여 App Acquisitions가 크게 개선되었음.
반응형
'Paper > Recommendation' 카테고리의 다른 글
| Session-based Recommendation with Graph Neural Networks (0) | 2020.03.28 |
|---|---|
| BPR: Bayesian Personalized Ranking from Implicit Feedback (1) | 2020.02.23 |
| Training Deep AutoEncoders for Collaborative Filtering (0) | 2020.01.20 |
| Item2Vec: Neural Item Embedding for Collaborative Filtering (2) | 2020.01.01 |
| Matrix Factorization Techniques for Recommender Systems (0) | 2019.12.14 |
댓글