
티스토리 뷰
Paper/Recommendation
Item2Vec: Neural Item Embedding for Collaborative Filtering
기내식은수박바 2020. 1. 1. 19:03반응형
Abstract
- 많은 협업 필터링 (CF, Collaborative Filtering) 알고리즘은 아이템 유사도를 생성하기 위해 아이템-아이템 간 관계를 분석한다는 점에서 아이템 기반이라고 할 수 있음.
- 최근 자연어 처리 분야에서의 연구들 중 일부는 뉴럴 임베딩 알고리즘을 사용하여 단어의 잠재 표현을 학습하는 것을 제시했음.
- 이 방법들 중 Word2Vec으로 알려진, Negative Sampling 을 이용한 Skip-gram (SGNS) 은 다양한 언어학적 작업에서 좋은 결과를 가져왔음.
- 이 논문에서, 우리는 아이템 기반 CF가 동일한 프레임워크의 뉴럴 단어 임베딩으로도 만들 수 있다는 것을 보여줌.
- SGNS에서 영감을 받아, 우리는 Item2Vec이라고 이름 붙인, 잠재 공간에서 아이템에 대한 임베딩을 만드는 아이템 기반 CF 방법을 설명함.
- 이 방법은 유저 정보를 이용할 수 없을 때조차도 아이템-아이템 관계를 추론할 수 있음.
- 우리는 대규모 데이터셋에서 Item2Vec의 효과를 증명하고 SVD와의 경쟁력을 보여주는 실험 결과를 제시함.
Index Terms
- skip-gram, word2vec, neural word embedding, collaborative filtering, item similarity, recommender systesm, market basket analysis, item-item collaborative filtering.
1. Introduction
- 아이템 유사도를 계산하는 것은 현대 추천 시스템의 블록을 구성하는 핵심임.
- 많은 추천 알고리즘은 유저와 아이템을 동시에 저차원 임베딩으로 학습하는 것에 집중되있는 반면, 아이템 유사도를 계산하는 것은 그 자체가 하나의 목적임.
- 아이템 유사도는 다양한 추천 작업에서 온라인 Retailers에 의해 광범위하게 사용됨.
- 이 논문은 유저와 상관없이 저차원 공간에 아이템을 임베딩하여 아이템 유사도를 학습하는 간과된 작업을 다룸.
- 아이템 기반 유사도는 온라인 Retailers이 단일 아이템을 기반으로 한 추천을 위해 사용됨.
- 예를 들어 윈도우 10 앱 스토어에서, 각 앱이나 게임의 세부 정보 페이지에는 "People also like" 라는 제목의 유사한 다른 앱들의 리스트가 포함되어 있음.
- 이 리스트는 Figure 1 과 같이 기존 앱과 유사한 아이템의 전체 페이지 추천 리스트로 확장될 수 있음.

- 단일 아이템과 유사하다는 것만을 기반으로 한, 유사 추천 리스트는 대부분의 온라인 스토어 (ex. Amazon, Netflix, Google Play, iTunes store and many others) 에 존재함.
- 단일 아이템 추천은 더 "전통적인 (Traditional)" 유저-아이템 추천과는 다름.
- 왜냐하면 이들은 보통 특정 아이템에 대한 명시적인 유저 관심 맥락과 명시적 유저 구매 의도로 나타나기 때문임.
- 따라서, 아이템 유사도 기반 단일 아이템 추천은 종종 유저-아이템 추천보다 더 높은 클릭 비율 (CTR, Click-Through Rates) 을 가지며, 결과적으로 판매량이나 수익의 더 큰 몫을 책임짐.
- 아이템 유사도 기반 단일 아이템 추천은 다양한 추천 작업에서 사용됨 :
- "Candy Rank" : 유사한 아이템 (보통 더 낮은 가격) 추천은 결제 직전 체크아웃 페이지에서 제시됨.
- "Bundle" : 일부 아이템 집합이 그룹화 되어 함께 추천됨.
- 결국, 아이템 유사도는 온라인 스토어에서 더 좋은 탐사와 발견을 위해 사용되며, 종합적인 유저 경험을 향상시킴.
- 유저에 대한 느슨한 (Slack) 변수들을 정의하여 암묵적으로 아이템들 사이의 연결성을 학습하는 유저-아이템 CF 방법은 아이템 관계를 직접 학습하기 위해 최적화하는 방법보다 더 좋은 아이템 표현을 생성함.
- 또한, 아이템 유사도는 아이템-아이템 관계에서 표현을 직접 학습하는 것을 목표로 두는 아이템 기반 CF 알고리즘의 핵심이기도 함.
- 아이템 기반 CF 방법이 요구되는 시나리오가 몇 가지 있음 :
- 대규모 데이터셋에서, 아이템 수보다 유저 수가 훨씬 더 많을 때, 아이템만 단독으로 모델링하는 방법의 계산 복잡도는 유저와 아이템을 동시에 모델링하는 방법보다 훨씬 더 낮음.
- 예를 들어, 온라인 뮤직 서비스들은 수만 명의 아티스트 (아이템) 가 있고, 등록된 유저는 수억 명일지도 모름.
특정한 시나리오에서는, 유저-아이템 관계를 사용할 수 없는 경우도 있음.
- 예를 들어, 오늘날 온라인 쇼핑의 대부분이 명시적인 유저 식별 과정 없이 이루어짐.
- 대신, 사용 가능한 정보는 각 세션 (Per Session) 임.
- 이러한 세션을 "유저"로 다루는 것은 덜 유용할 뿐만 아니라 엄청나게 비용이 많이 듬.
- 최근 언어학적 연구에 대한 뉴럴 임베딩 방법이 발전함에 따라 최첨단 NLP 기능이 극적으로 향상됨.
- 이러한 방법들은 단어 사이의 의미론적, 구문론적 관계를 포착하는 저차원 벡터 공간에 단어와 구를 매핑하려고 시도함.
- 구체적으로 Word2Vec으로 알려진, Negative Sampling을 이용한 Skip-gram (SGNS) 방법은 다양한 NLP 작업에서 새로운 기록을 설정하며 (Set new Records), 그 어플리케이션은 NLP를 넘어 다른 도메인으로도 확장되었음.
- 이 논문에서, 우리는 아이템 기반 CF에 SGNS 적용을 제시함.
- 다른 도메인에서의 성공으로 인해 동기 부여받았으며, 우리는 조금 수정한 SGNS가 CF 데이터셋에서 서로 다른 아이템 사이의 관계를 포착할 수도 있다는 것을 제안함.
- 끝으로, 우리는 Item2Vec이라고 이름 붙인 SGNS의 수정된 버전을 제시함.
- 우리는 Item2Vec이 SVD를 사용한 아이템 기반 CF와 비교하여, 경쟁력 있는 유사도 측정을 유도할 수 있다는 것을 보여줌.
- 우리가 최첨단 결과를 달성했다고 주장하는 것이 아닌, 단지 아이템 기반 CF에 대한 SGNS의 또 다른 성공적인 어플리케이션을 보여주기 위한 것이라고 분명히 하는 것이 중요함.
- 따라서, 우리는 SVD 기반 모델을 우리 방법과 비교하고, 다른 더 복잡한 방법과의 비교는 추후의 연구로 남겨두는 것을 선택함.
2. Skip-Gram with Negative Sampling (SGNS) - Related work
- SGNS은 Mikolove el al (아래) 이 소개했던 뉴럴 단어 임베딩 방법임.
- 이 방법은 문장에서 한 단어와 그 단어 주위의 단어들 사이의 관계를 포착하는 단어 표현을 찾는 것을 목표로 둠.
- 유한한 어휘집합 (아래) 에서 단어 시퀀스 (아래) 가 주어졌을 때, Skip-gram의 목적은 수식 (1) 을 최대화하는 것임 :


- \(c\)는 문맥의 윈도우 크기 (\(w_{i}\)에 의존함)
- \(p\)(\(w_{j}\) | \(w_{i}\)) 는 소프트맥스 함수임 :

- \(u_{i}\ \in U\) (⊂ \(R^{m}\)) 그리고 \(v_{i}\ \in V\) (⊂ \(R^{m}\)) 은 각각 단어 \(w_{i} \in W\) 에서 타겟과 문맥 표현에 해당되는 잠재 벡터임.
- \(I_{W}\) ≜{1, ... , |W |} 과 파라미터 \(m\) 은 데이터셋 크기에 따라 경험적으로 선택됨.
- 수식 (2) 를 사용하는 것은 ▽\(p(w_{j}|w_{i})\) 의 계산 복잡도 때문에 비실용적이며, ▽\(p(w_{j}|w_{i})\) 는 보통 \(10^{5}\) ~ \(10^{6}\) 크기를 가진 어휘 집합 |\(W\)| 의 선형 함수임.
- Negative Sampling은 아래와 같이 수식 (2) 의 소프트맥스 함수를 대체함으로써 계산적 문제를 완화함.

- \(\sigma(x)\) = 1 / 1 + exp\((-x)\) 임.
- \(N\) 은 Positive Sample 별로 뽑히는 Negative Examples의 수를 결정하는 파라미터임.
- Negative 단어 \(w_{i}\) 는 3 / 4 제곱된 유니그램 분포에서 샘플링됨.
- 이 분포는 경험적으로 유니그램 분포보다 상당히 우수한 것으로 밝혀졌음.
- 희소 단어들과 빈번한 단어들 사이의 불균형을 극복하기 위해서, 다음과 같이 Subsampling 절차가 제시됨 :
- 입력 단어 시퀀스가 주어질 때, 우리는 확률 \(p(discard|w)\) = 1 - \(\sqrt{\rho \over{f(w)}}\) 와 함께 각 단어 \(w\) 를 버림.
- \(f(w)\) 는 단어 \(w\) 의 빈발도
- \(\rho\) 는 규정된 임계값 (Threshold)
- 이 절차는 학습 과정을 가속화 하고 희소 단어 표현을 상당히 향상시키는 것으로 기록됐음.
- 우리 실험에서도, Subsampling을 적용했을 때 동일한 향상을 관측했음.
- 결국, \(U\) 와 \(V\) 는 수식 1의 목적함수에 확률적 (Stochastic) 최적화를 적용하여 추정됨.
3. Item2Vec - SGNS for item-based CF
- CF 데이터의 맥락에서, 아이템들은 유저가 생성한 집합 (as User generated sets) 으로 주어짐.
- 유저와 아이템 집합 사이의 관계에 대한 정보는 항상 사용 가능한 것은 아니라는 것을 유의해야 함.
- 예를 들어, 우리에게 주문을 한 사람에 대한 정보가 아무것도 없는 주문에서 생성된 데이터셋이 제공될 수 있음.
- 다른 말로 얘기하면, 다수의 아이템 집합이 동일한 유저에 속할 수 있는 시나리오가 있지만, 이 정보는 제공되지 않음.
- Section 4에서, 우리 방법이 이러한 시나리오 또한 다루는 것을 보여주는 실험 결과를 제시함.
우리는 아이템 기반 CF에 SGNS를 적용하는 것을 제시함.
- CF 데이터에 SGNS를 적용하는 것은 일단 단어 시퀀스가 아이템 집합 (a set or basket of items) 과 동일하다고 인식하면 간단함.
- 따라서, 지금부터 우리는 용어 "word" 와 "item"을 서로 바꿔서 사용할 것임.
- 시퀀스에서 집합으로 옮김으로써, 공간적 / 시간적 정보는 잃어버림.
- 이 논문에서, 유저가 생성한 순서 / 시간에 관계없이 동일한 집합을 공유하는 아이템이 유사하다고 생각되는 정적인 환경을 가정하므로 우리는 이 정보를 버리기로 선택함.
- 이 가정은 다른 시나리오에서는 유효하지 않을 수 있지만, 우리는 이 논문 범위 밖에서 이러한 시나리오들을 계속 다룰것임.
- 우리가 공간적 정보를 무시하기 때문에, Positive Sample 로써 동일한 집합을 공유하는 각 아이템 쌍을 다룸.
- 이는 집합 크기에서 결정된 윈도우 크기를 암시함.
- 구체적으로, 아이템 집합이 주어질 때, 수식 (1) 의 목적함수는 다음과 같이 수정됨 :
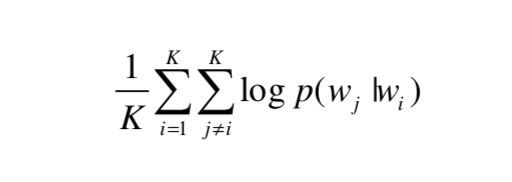
- 또 다른 옵션은 수식 (1) 의 목적함수를 그대로 유지하고, 실행시간동안 각 아이템 집합을 섞는 것임.
- 실험에서, 우리는 두 옵션 모두 동일하게 수행하는 것을 관찰했음.
- 과정의 나머지 부분은 Section 2에서 설명한 알고리즘과 동일함.
- 우리는 설명한 이 방법을 "Item2Vec" 이라고 이름을 붙임.
- 이 작업에서, 우리는 \(i\) 번째 아이템의 최종 표현으로 \(u_{i}\) 를 사용했으며, 아이템 쌍 사이의 관련성은 코사인 유사도에 의해 계산됨.
- 다른 옵션들은 \(v_{i}\), 추가적인 구성은 \(u_{i} + v_{i}\), 또는 결합 \([u^{T}_{i}, v^{T}_{i}]^{T}\) 를 사용하는 것임 (아래).

- 마지막 두 개의 옵션은 가끔 우수한 표현을 생성한다는 점을 유의해야 함.
4. Experimental Results
- 이 Section에서, 우리는 Item2Vec 방법의 실증적인 추정을 제공함.
- 우리는 아이템에 대한 메타데이터가 존재하는지 여부에 따라 질적 그리고 양적인 결과를 모두 제공함.
- 아이템 기반 CF 알고리즘의 Baseline으로 아이템-아이템 SVD를 사용했음.
4.1 Datasets
- 우리는 두 가지 서로 다른 유형의 데이터셋에 대한 방법을 비공개로 평가함.
첫 번째 데이터셋은 Microsoft XBOX Music service에서 검색된 유저-아티스트 데이터임.
- 이 데이터셋은 9M 이벤트로 구성되며, 각 이벤트는 유저-아티스트 관계로 구성되고, 이는 유저가 구체적인 아티스트의 노래를 재생했다는 것을 의미함.
- 데이터셋은 732K 유저와 49K의 다른 아티스트를 포함함.
두 번째 데이터셋은 Microsoft Store의 물리적인 상품 주문들을 포함함.
- 하나의 주문은 그 주문을 한 유저에 대한 어떠한 정보도 없이 아이템 바구니 (Basket) 에 의해 주어짐.
- 따라서, 이 데이터셋 정보는 우리가 유저와 아이템 사이를 결합할 수 없다는 점 때문에 더 부족함.
- 이 데이터셋은 379K 주문 (단일 아이템 이상을 포함하는) 과 1706의 다른 아이템들로 구성됨.
4.2 Systems and parameters
- 우리는 이 두 데이터셋에 Item2Vec을 적용했음.
- 최적화는 SGD (Stochastic Gradient Descent) 로 이루어짐.
- 우리는 20 Epochs 로 알고리즘을 실행했음.
- 두 데이터셋에 \(N\) = 15 로 Negative Sampling 수치를 설정함.
- 차원 파라미터 \(m\) 은 각각 Music은 100, Store는 40으로 설정했음.
- 추가로 Subsampling 값인 \(\rho\) 는 각 데이터셋마다 Music -> \(10^{-5}\), Store -> \(10^{-3}\) 으로 적용했음.
- 서로 다른 파라미터 값으로 설정한 이유는 데이터셋 크기가 다르기 때문임.
우리는 SVD 기반 아이템-아이템 유사도 시스템과 우리 방법을 비교함.
- 이 비교를 위해, SVD를 아이템 수 크기의 사각 행렬에 적용하는데, 여기서 \((i, j)\) 엔트리는 \((w_{i}, w_{j})\) 는 데이터셋에서 Positive 쌍으로 나타난 횟수를 포함함.
- 그런 다음, 우리는 각 엔트리를 행과 열 합계의 내적 제곱근 (Square Root of the Product) 에 따라 정규화했음.
- 결국, 잠재 표현은 \(US^{1 \over{2}}\) 의 행으로 주어짐.
- \(S\) 는 대각선이 Top \(m\) 특이값을 포함하는 대각 행렬 (S is a diagonal matrix that its diagonal contains the top m singular values)
- \(U\) 는 해당하는 왼쪽 특이값을 열로 포함하는 행렬 (U is a matrix that contains the corresponding left singular vectors as columns)
- 아이템 간 관련성 (Affinity) 은 아이템 표현들의 코사인 유사도로 계산됨.
- 이 Section을 통해, 우리는 이 방법을 "SVD"라고 이름 붙임.
4.3 Experiments and results
- Music 데이터셋은 장르 메타데이터를 제공하지 않음.
- 따라서 각 아티스트에 대해, 장르-아티스트 카탈로그 형식을 만들기 위해 웹에서 장르 메타데이터를 검색했음.
- 그런 다음, 학습 된 표현과 장르 사이의 관계를 시각화 하기 위해 이 카탈로그를 사용했음.
- 이는 유용한 표현이 그러한 장르에 따라 아티스트를 군집화시킬 것이라는 가정에 의해 동기부여됨.
- 이때문에, 우리는 다음과 같은 구별되는 장르들에 대해 장르별 Top 100의 인기있는 아티스트를 포함하는 하위집합을 생성했음 :
- R&B / Soul
- Kids
- Classical
- Country
- Electronic / Dance
- Jazz
- Latin
- Hip Hop
- Reggae / Dancehall
- Rock
- World
- Christian / Gospel
- Blues / Folk
- 우리는 아이템 벡터의 차원을 2로 감소시키기 위해 코사인 커널을 이용한 t-SNE를 적용했음.
- 그런 다음, 각 아티스트를 장르에 따라 색깔 점으로 매칭함.
- Figures 2 (a) 와 2 (b) 는 각각 Item2Vec과 SVD에 대해 t-SNE에 의해 만들어진 2차원 임베딩을 표현함.

- 볼 수 있듯이, Item2Vec은 더 좋은 클러스터링을 제공함.
- Fig 2 (a) 에서 비교적 동질적인 영역들의 일부가 색상이 다른 아이템으로 오염되었음을 추가로 관찰함.
- 우리는 이러한 사례들 중 많은 것들이 웹에서 잘못 표기되거나 혼합된 장르를 가진 아티스트에서 비롯된다는 것을 알아냈음.
- Table 1은 주어진 아티스트와 관련된 장르 (웹에서 검색한 메타데이터에 따라) 가 부정확하거나 최소한 Wikipedia에 모순되는 몇 가지 예시를 보여줌.

- 따라서, 우리는 Item2Vec 같은 모델 기반 사용이 잘못 표기된 데이터 발견에 유용할 수도 있으며, 심지어 간단한 KNN (k nearest neighbor) 분류기를 사용하여 정확한 레이블에 대한 제안까지 제공한다고 결론지음.
- 유사도 품질을 정량화 하기 위해, 우리는 아이템과 그 아이템과 가장 가까이 있는 이웃 아이템 사이의 장르 일관성을 테스트했음.
- 우리는 Top \(q\) (다양한 \(q\) 값에 대해) 개의 인기있는 아이템들에 대해 반복하여 수행했으며, 이들의 장르가 이들 주위의 가장 가까운 k개의 아이템 장르와 일치하는지 체크함.
- 이는 단순하게 다수결 (Majority Voting) 로 수행함.
- 우리는 서로 다른 이웃 크기 (k = 6, 8, 10, 12, 16) 로 동일한 실험을 진행했으며, 상당한 결과 변화는 관찰되지 않았음.
- Table 2는 k = 8 일 때 관찰된 결과를 제시함.

- 우리는 꾸준하게 Item2Vec이 SVD 모델 보다 더 좋다는 것을 관찰했으며, 이 두 모델 사이의 차이는 \(q\) 가 증가할때 마다 점점 커짐.
- 이는 덜 유명한 아이템들에 대해, Item2Vec이 SVD 보다 더 좋은 표현을 생성한다는 것을 암시할 수 있으며, 이는 Item2Vec이 유명한 아이템을 Subsample하고 그러한 아이템들의 인기에 따라 Negative Example을 Sampling하기 때문에 놀랍지 않음.
- 우리는 추가로 10K의 비인기 아이템 하위집합 (Table 2의 마지막 행) 에 동일한 "장르 일관성" 테스트를 적용하여 이 가설을 검증함.
- 우리는 어떤 아이템에 해당하는 아티스트를 재생한 유저가 15명 미만일 경우, 비인기 아이템으로 정의함.
- 정확도는 Item2Vec이 68%, SVD가 58.4%를 획득했음.
- Item2Vec과 SVD 사이의 질적 비교는 각각 Music과 Store 데이터셋에 대해 Table 3 ~ 4 에 보여짐.

- Table들은 Seed 아이템들과 이와 가장 가까운 5개 이웃들을 보여줌.
- 장르보다 더 높은 품질의 아이템 유사도를 검사할 수 있다는 것이 이 비교의 주된 이점임.
- 게다가, Store 데이터셋은 유용한 태그 / 레이블이 없기 때문에, 질적인 평가가 불가피함.
- 우리는 이 두 데이터셋들에 대해 Item2Vec이 SVD보다 Seed 아이템과 더 관련 있는 리스트를 제공한다는 것을 관찰함.
- 더욱이, 우리는 비록 Store 데이터셋이 더 부족한 정보를 포함할지라도, Item2Vec이 꽤 아이템 관계를 잘 추론하고 있는 것을 봄.
5. Conclusion
- 이 논문에서, 우리는 아이템 기반 CF에 대한 뉴럴 임베딩 알고리즘인 Item2Vec을 제시했음.
- Item2Vec은 작은 수정을 거친 SGNS 기반임.
- 우리는 SVD 기반 아이템 유사도 모델과 비교했을 때, Item2Vec의 효과를 증명하는 질적, 그리고 양적인 추정 모두를 보여줌.
- Item2Vec이 SVD 베이스라인 모델보다 더 좋은 아이템 표현을 생성한다는 것을 관찰했으며, 이 둘 사이의 격차는 비인기 아이템에서 좀 더 커짐.
- Item2Vec이 인기 아이템의 Subsampling과 함께 Negative Sampling을 사용한다는 사실로 이것을 설명함.
- 추후에는 우리가 아래와 같은 더 복잡한 CF 모델을 살펴보고, Item2Vec과 이 모델들을 비교하는 것을 계획하고 있음.
반응형
'Paper > Recommendation' 카테고리의 다른 글
| Session-based Recommendation with Graph Neural Networks (0) | 2020.03.28 |
|---|---|
| BPR: Bayesian Personalized Ranking from Implicit Feedback (1) | 2020.02.23 |
| Training Deep AutoEncoders for Collaborative Filtering (0) | 2020.01.20 |
| Wide & Deep Learning for Recommender Systems (0) | 2020.01.19 |
| Matrix Factorization Techniques for Recommender Systems (0) | 2019.12.14 |
댓글