
티스토리 뷰
Paper/Recommendation
Training Deep AutoEncoders for Collaborative Filtering
기내식은수박바 2020. 1. 20. 23:53반응형
Abstract
- 이 논문은 Time-Split 넷플릭스 Dataset에서 이전 모델들 보다 더 나은 성능을 내는 추천 시스템의 등급 예측 작업 모델을 제시함.
- 우리 모델은 어떠한 Layer-Wise Pre-training 없이 End-to-End 로 학습하며, 6개 계층을 가진 Deep Autoencoder를 기반으로 함.
- 우리는 이것을 경험적으로 증명함 :
- a) Deep Autoencoder 모델은 얕은 (Swallow) 모델 보다 훨씬 더 일반화 시킴.
- b) Negative Part를 이용한 비선형 활성함수는 심층 (Deep) 모델을 훈련하는 데 매우 중요함.
- c) Overfitting을 방지하기 위해 Dropout 같은 규제 기법을 많이 사용하는 것이 필요함.
- 또한, 우리는 CF (Collaborate Filtering) 의 자연적인 희소성 (Natural Sparseness) 을 극복하기 위해 반복적인 Output Re-feeding 에 기반한 새로운 훈련 알고리즘을 제안함.
- 새로운 알고리즘은 훈련을 가속화하며, 모델 성능을 상당히 향상시킴.
- 코드 URL : https://github.com/NVIDIA/DeepRecommender
1. Introduction
- Amazon, Netflix, Spotify 같은 사이트들은 유저에게 아이템을 제안하기 위해 추천 시스템을 사용함.
- 추천 시스템은 두 가지 카테고리로 나뉠 수 있음 :
- Context-based Recommendation
- Personalized Recommendation
Context-based Recommendation
- 이 추천은 지역, 날짜, 시간 같은 상황적 요인들을 고려함.
Personalized Recommendation
- 이 추천은 보통 CF 방법을 사용하여 유저에게 아이템을 제안함.
- 유저 관심사는 시스템 내 다른 유저들의 취향과 선호도를 분석하고, 이들 사이의 "유사도 (Similarity)" 를 암묵적으로 추론하여 예측함.
- 기본적인 가정은 비슷한 취향을 가진 두 사람이 무작위로 선택된 두 사람보다 아이템에 대해 같은 의견을 가질 가능성이 더 높다는 것임.
추천 시스템을 설계하는데 있어서, 목표는 예측 정확도를 향상시키는 것임.
- Netflix Prize 컨테스트에서는 이러한 문제에서 가장 유명한 예제를 제공함.
- Netflix는 유저 등급을 예측하는 알고리즘 정확도를 상당히 높이기 위해 Netflix Prize를 개최했음.
- 이것이 전형적인 CF 문제임 :
- \(i\) 번째 유저, \(j\) 번째 아이템에 주어진 등급을 설명하는 \((i, j)\) 엔트리의 \(m \times n\) 행렬인 \(R\) 에서 결측 엔트리들을 추론하는 것.
- 그런 다음, 성능은 \(RMSE\) \((Root\) \(Mean\) \(Square\) \(Error)\) 를 사용하여 측정됨.
1.1 Related Work
- 딥 러닝은 이미지 인식, 자연어 이해, 강화 학습에서 돌파구로 이끌어 주고 있음.
- 자연스럽게, 이러한 성공들이 추천 시스템에서도 딥러닝 사용에 대해 흥미가 생기도록 함.
- 추천 시스템에서 딥러닝을 사용한 첫 번째 시도는 RBM (Restricted Boltzman Machines) 과 관련있음.
- 일부 최신 접근법들은 Autoencoder, Feed-forward Neural Network, RNN (Recurrent Recommender Network) 를 사용함.
- 다수의 유명한 MF (Matrix Factorization) 기법들은 차원 감소의 형태로 생각될 수 있음.
- 따라서, 마찬가지로 이 작업에 Deep Autoencoder를 적용시키는 것은 자연스러움.
- \(I\)-\(AutoRec\) (아이템 기반 Autoencoder), \(U\)-\(AutoRec\) (유저 기반 Autoencoder) 는 그러한 작업들을 처음 성공한 시도들임.
딥러닝을 사용하지 않은 많은 종류의 CF 접근법들이 있음.
- 특히, ALS (Alternating Least Squares) 같은 MF 기법과 확률적 MF 기법이 대중적으로 많이 사용됨.
- 가장 강건한 (Robust) 시스템은 Netflix Prize 대회 위닝 솔루션처럼 몇 가지 아이디어를 통합할 수도 있음.
- 또한, Netflix Prize 데이터는 각 등급이 만들어진 시간인 시간적 신호를 포함함.
- 따라서, 일부 전통적인 CF 접근법들은 TimeSVD++ 같은 시간적 정보와 더 최근에는 순환 추천 네트워크 같은 RNN 기반 기법들을 통합하기 위해 확장되었음.
2. Model
- 우리 모델은 일부 중요한 차이점을 이용한 \(U\)-\(AutoRec\) 방법에서 영감을 받았음.
- 어떠한 Pre-Training 없이 이를 수행하기 위해서, 우리는 다음과 같이 수행했음 :
- "Scaled Exponential Linear Units" (SELUs) 를 사용함.
- 높은 Dropout 비율을 사용함.
- 훈련동안 반복적으로 Output을 Re-feeding 함.
Autoencoder
- Autoencoder는 두 개의 Transformations를 구현한 네트워크임.
- Encoder - \(encode(x)\) : \(R^{n}\) → \(R^{d}\)
- Decoder - \(decode(z)\) : \(R^{d}\) → \(R^{n}\)
- Autoencoder의 "목표"는 \(x\) 와 \(f(x)\) = \(decode(encode(x))\) 사이의 에러 측정치가 최소화 되는 그러한 데이터의 \(d\) 차원 표현을 얻는 것임.
- Figure 1은 일반적인 4계층 Autoencoder 네트워크를 묘사함.
- Noise가 encoding 단계동안 데이터에 추가되면, Autoencoder는 \(de\)-\(noising\) 이라 불림.
- Autoencoder는 차원을 감소시키는 훌륭한 도구이며, PCA (Principle Component Analysis) 의 엄격한 일반화로 생각될 수 있음.
- 비선형 활성화 없이 "code" 계층만 있는 Autoencoder는 MSE (Mean Square Error) 손실을 최적화하도록 훈련되는 경우, encoder에서 PCA Transformation 을 학습할 수 있어야 함.
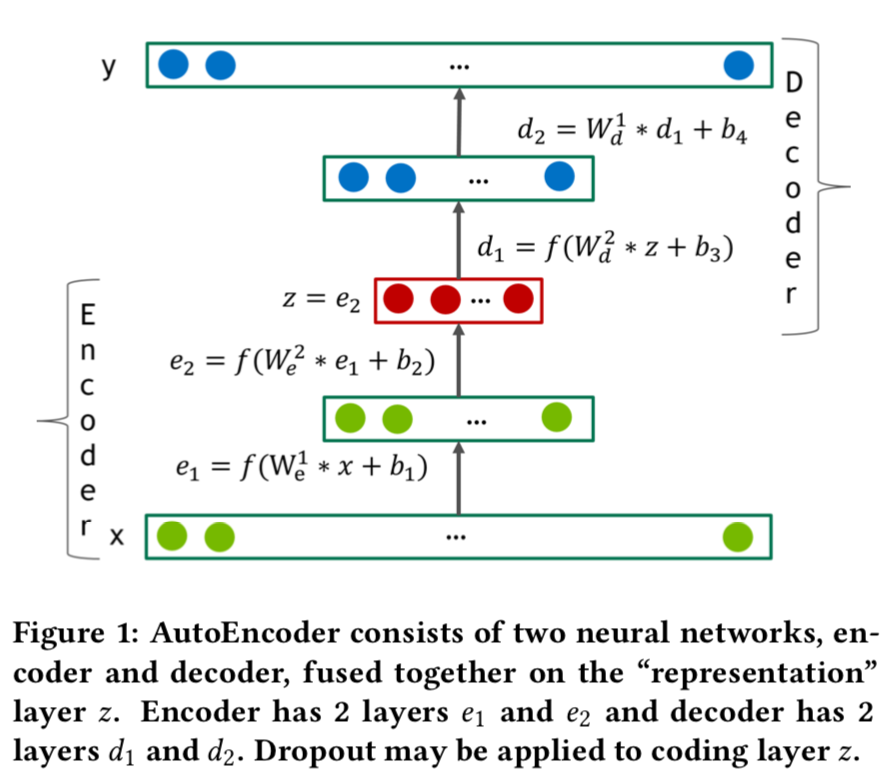
우리 모델에서, Autoencoder의 Encoder와 Decoder 두 개의 Part 모두 \(l\) = \(f(W\) \(*\) \(x\) \(+\) \(b)\) 를 계산하는 전통적인 완전 연결 계층을 가진 Feed-forward Neural Network로 구성되며, \(f\) 는 일부 비선형 활성화 함수임.
- 활성화 함수의 범위가 데이터 범위보다 더 작다면, Decoder의 마지막 계층은 선형을 유지해야 함.
- 우리는 은닉 계층의 활성화 함수 \(f\) 가 0이 아닌 Negative Part를 포함하는 것이 매우 중요하다는 것을 발견했으며, 대부분의 실험에서 SELU 단위를 사용함.
- Decoder가 Encoder 아키텍처를 반영한다면 (우리 모델처럼), Decoder의 가중치 \(W^{l}_{d}\) 를 해당 계층 \(l\) 에서 변환된 Encoder 가중치 \(W^{l}_{e}\) 와 동일하도록 제한할 수 있음.
- 그러한 Autoencoder는 \(Constrained\) 또는 \(tied\) 라 불리며, Unconstrained한 것보다 자유 파라미터 (Free Parameters) 가 거의 두 배 적음.
Forward pass and Inference
- Forward Pass (그리고 추론 (Inference)) 동안, 모델은 훈련 집합 \(x\) \(∈\) \(R^{n}\) 에서 등급 벡터로 표현된 유저를 취하며, 여기서 \(n\) 은 아이템 갯수임.
- \(x\) 가 매우 Sparse한 반면, Decoder의 Output 인 \(f(x)\) \(∈\) \(R^{n}\) 은 Dense하고, Corpus의 Corpus 내 모든 아이템에 대한 등급 예측을 포함하고 있다는 점에 유의해야 함.
2.1 Loss Function
- 유저 표현 벡터 \(x\) 에서 0을 예측하는 것은 타당하지 않으므로, 아래 연구 방식을 따르고 MMSE (Masked Mean Squared Error) 손실을 최적화함 :
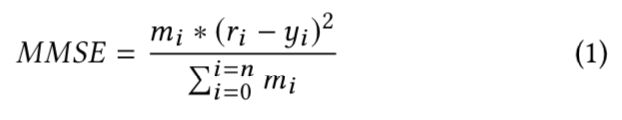
- 각 파라미터 설명
- \(r_{i}\) 는 실제 등급 (Actual Rating)
- \(y_{i}\) 는 재구성되거나 예측 등급
- \(m_{i}\) 는 \(r_{i}\) ≠ 0일 경우 값 1, 그렇지 않으면 값 0을 가지는 마스크 함수
- RMSE 점수와 MMSE 점수 사이의 간단한 관계가 있다는 것을 유의해야 함 :
- \(RMSE\) = \(\sqrt{MMSE}\)
2.2 Dense re-feeding
- 훈련과 추론 과정 동안, Input \(x\) \(∈\) \(R^{n}\) 은 매우 Sparse 함.
- Why ? - 현실적으로 어떤 사용자도 모든 아이템을 평가할 수 없음.
- 반면에, Autoencoder의 Output \(f(x)\) 은 Dense 함.
\(Perfect\) \(f\)로 이상적인 시나리오를 생각해보겠음.
- \(f(x)_{i}\) = \(x_{i}\), \(∀_{i}\) : \(x_{i}\) ≠ 0, 그리고 \(f(x)_{i}\) 는 정확하게 아이템 \(i\) : \(x_{i}\) = 0 에 대한 모든 유저의 \(future\) 등급을 예측함.
- 이는 유저가 새로운 아이템 \(k\) 에 등급을 매긴다면 (새로운 벡터 \(x`\) 가 만들어짐), \(f(x)_{k}\) = \(x`_{k}\) 와 \(f(x)\) = \(f(x`)\) 이 됨.
- 따라서, 이러한 이상적인 시나리오에서, \(y\) \(=\) \(f(x)\) 는 잘 훈련된 Autoencoder의 \(fixed\) \(point\) 이어야 함 : \(f(y)\) \(=\) \(y\)
- \(fixed\) \(point\) 제한을 명시적으로 적용하고 Dense 훈련 업데이트를 수행하기 위해서, 다음과 같이 반복적인 Dense Re-feeding 스텝 (3 및 4) 로 모든 최적화 반복을 증가시킴.
- Sparse한 \(x\) 가 주어질 때, 수식 (1) 을 사용하여 Dense한 \(f(x)\) 와 손실을 계산함 (Forward Pass).
- Gradients를 계산하고, 가중치 갱신을 수행함 (Backward Pass).
- \(f(x)\) 를 새로운 예시로 다루고, \(f(f(x))\) 를 계산함. 현재 \(f(x)\) 와 \(f(f(x))\) 모두 dense하며, 수식 1에서 계산한 손실은 모두 0이 아닌 값인 \(m\) 을 가짐 (Second Forward Pass).
- Gradients를 계산하고, 가중치 갱신을 수행함 (Second Backward pass).
- 스텝 (3), (4) 는 또한 매 반복마다 한 번이상 수행될 수 있음.
3. Experiments and Results
3.1 Experiment Setup
- 등급 예측 작업의 경우, 무작위로 결측된 등급을 예측하는 대신, \(Past\) 등급이 주어졌을 때 \(future\) 등급을 예측하는 것이 가장 관련 있음.
- 평가를 위해, 우리는 원래 Netflix Prize 훈련을 시간에 따라 여러 훈련 간격으로 분할하여 아래 연구를 정확히 따랐음.
- 훈련 간격은 테스트 간격보다 더 일찍 도달하는 등급을 포함함.
- 그런 다음, 테스트 간격은 테스트 간격의 각 등급이 각 하위집합에서 나타날 확률을 50% 가지기 때문에, 무작위로 테스트와 검증 (Validation) 하위 집합으로 나눔.
- 훈련 집합에 나타나지 않은 유저와 아이템은 테스트와 검증 하위집합에서 제거됨.
- Table 1은 데이터셋의 세부사항을 제공함.

- 우리 실험 대부분에서, Batch size = 128, Learning rate = 0.001, Momentum = 0.9 인 SGD을 사용함.
- 파라미터를 초기화 하기 위해 Xavier 초기화를 사용함.
- 아래 연구와 달리, 우리는 어떤 Layer-wise Pre-training도 사용하지 않았음.
- 우리는 올바른 활성 함수를 선택했기 때문에 성공적으로 그렇게 할 수 있었다고 믿음 (Section 3.2 참고).
3.2 Effects of the Activation Types
- 서로 다른 활성 함수 사용의 효과를 살펴보기 위해, 우리는 딥러닝에서 가장 유명한 선택들 중 일부를 각 은닉층에 128개 유닛을 가진 4 계층 Autoencoder에서 테스트 했음 :
- Sigmoid
- ReLU (Rectified Linear Units)
- \(max\) (\(relu(x)\), 6) 또는 ReLU6
- tanh (Hyperbolic Tangent)
- ELU (Exponential Linear Units)
- LReLU (Leaky ReLU)
- SELU (Scaled Exponential Linear Units)
- 등급이 1 ~ 5 로 정규화 됐기 때문에, 우리는 tanh, sigmoid 기반 모델에 대해서는 Decoder의 마지막 계층을 선형으로 유지함.
- 이외에 모든 다른 모델에서는 활성화 함수가 모든 계층에 적용됨.
- 우리는 이 작업에서 ELU, SELU, LReLU가 Sigmoid, ReLU, ReLU6, tanh 보다 훨씬 더 잘 수행한다는 것을 발견했음.
- Figure 2는 명백하게 이를 증명함.
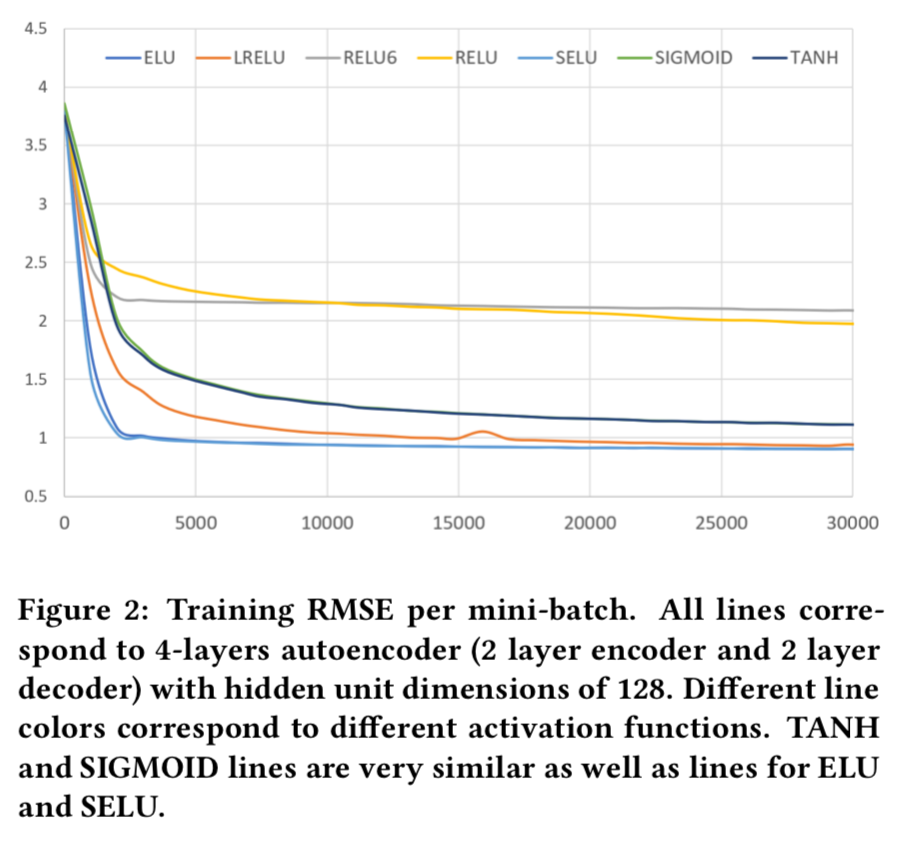
- 잘 작동하는 활성화와 그렇지 않은 활성화를 분리하는 것처럼 보이는 두 가지 특성이 있음 :
- a) 0이 아닌 음인 부분 (Non-zero Negative Part)
- b) 한없이 양인 부분 (Unbounded Positive Part)
- 따라서, 우리는 이 설정에서 이러한 특성들이 성공적인 훈련을 위해 중요하다고 결론을 냄.
- 그러므로, 우리는 SELU 활성화 유닛을 사용하고, 성능을 위해 SELU 기반 네트워크를 조정함.
3.3 Over-fitting the Data
- 훈련에 사용한 가장 큰 데이터셋인, Table 1의 "Netflix Full" 에는 477K의 사용자가 제공한 98M 등급이 포함되어 있음.
- 이 집합에서 영화의 수 (즉, 아이템) 인 \(n\) 은 \(17,768\) 임.
- 따라서, Encoder의 첫 번째 계층은 \(d\) \(*\) \(n\) \(+\) \(d\) 가중치를 가질 것이며, 여기서 \(d\) 는 계층의 유닛 수를 의미함.
- 현대 딥러닝 알고리즘과 하드웨어의 경우에서, 이는 상대적으로 작은 작업임.
- 우리가 단일 계층을 가진 Encoder와 Decoder로 시작하면, \(d\) 가 512만큼 작아도 훈련 데이터에 빠르게 Overfitting 될 수 있음.
- Figure 3은 분명하게 이를 증명함.
- Unconstrained Autoencoder를 Constrained로 바꾸는 것은 오버피팅을 감소시키지만, 이 문제를 완벽히 해결하는 것은 아님.
3.4 Going Deeper
- 계층을 더 넓게 (Wider) 만드는 것은 훈련 손실을 감소시키지만, 더 많은 계층을 추가하는 것은 종종 네트워크의 일반화 능력과 관련있음.
- 이 일련의 실험에서, 우리는 이것이 사실이라는 것을 증명함.
- 오버피팅을 쉽게 피하기 위해서 모든 은닉층에 충분히 작은 차원 (\(d\) = 128) 을 선택하고, 더 많은 계층들을 추가함.
- Table 2는 계층수와 추정 정확도 간 긍정적인 상관관계가 있다는 것을 보여줌.
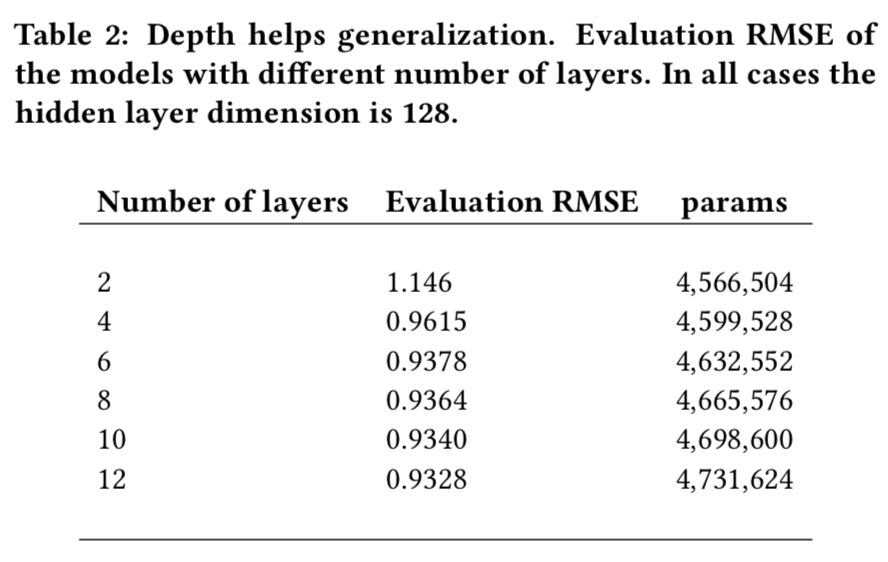
- encoder와 decoder가 1 계층에서 3 계층으로 진행하는 것은 RMSE 추정 값 ( 1.146 -> 0.9378) 에서 좋은 향상을 제공함.
- 그 후에, 맹목적으로 더 많은 계층을 추가하는 것은 도움이 되지만, 반환값을 감소시킴.
- 단일 (\(d\) = 256) 계층을 가진 encoder와 decoder 모델은 9,115,240개의 파라미터를 가지는데, 이는 이러한 딥러닝 모델 중 다른 것들 보다 거의 2배 이상인 반면, 훨씬 더 안좋은 평가 RMSE를 가짐.
3.5 Dropout
- Section 3.4 는 많은 수의 작은 계층들을 추가하는 것이 결국 반환 값 감소를 일으킨다는 것을 보여줌.
- 따라서, 우리는 더 광범위하게 하이퍼 파라미터와 모델 아키텍처를 가지고 실험을 시작함.
- 가장 괜찮은 모델은 다음 아키텍처를 가짐 :
- \(n\), 512, 512, 1024, 512, 512, \(n\) 이며, 이는 encoder (512, 512, 1024) 의 3 계층을 의미함.
- 그러나, 이 모델은 아무런 정규화 (Regularization) 없이 훈련되면, 빠르게 Overfitting됨.
- 이를 정규화 (Regularize) 하기 위해서, 일부 Dropout 수치들로 테스트 했으며, 흥미롭게도 높은 Drop 확률 (즉. 0.8) 값이 가장 좋다고 판명됐음.
- RMSE 추정에 대해서는 Figure 4를 보면됨.
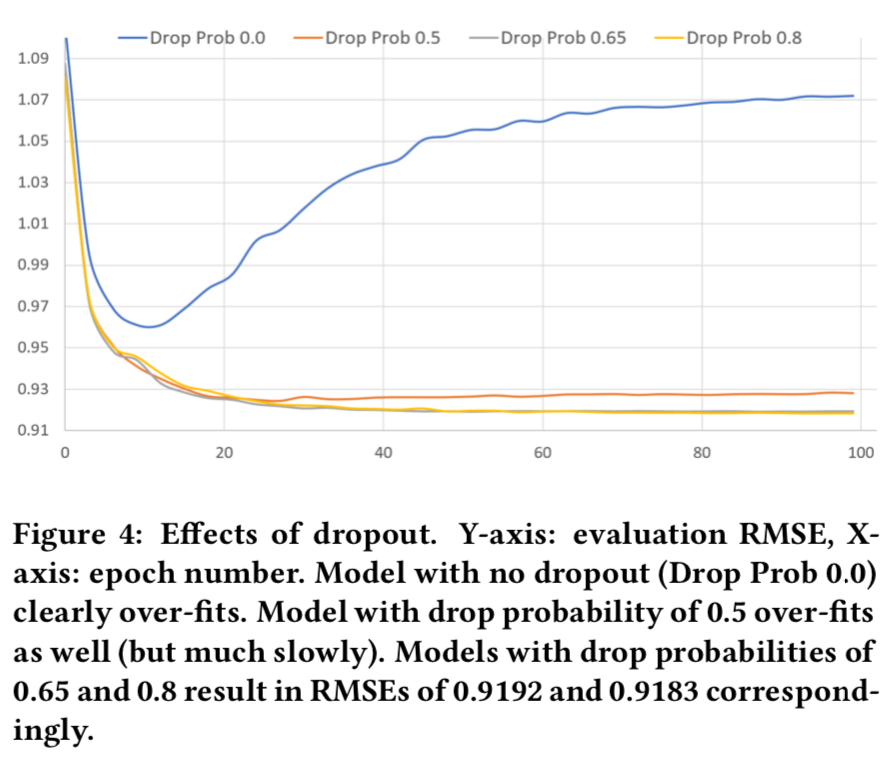
- 우리는 Encoder Output (즉, \(f(x)\) = \(decode(dropout(encode(x)))\)) 에만 Dropout을 적용함.
- 우리는 모델의 모든 계층마다 Dropout을 적용하려고 했지만, 이 때문에 훈련 수렴 (Convergence) 이 억제되고 일반화가 개선되지 않았음.
3.6 Dense Re-feeding
- 반복적인 Dense Re-feeding (Section 2.2) 은 6 계층 모델 (n, 512, 512, 1024, \(dp\)(0.8), 512, 512, n) 에 대한 추정 정확도의 추가적인 향상을 제공함.
- 여기서 각 파라미터는 Input, Hidden Units, 또는 Output의 수를 나타내며, \(dp\)(0.8) 은 0.8의 Drop 확률을 가진 Dropout 계층임.
- Output Re-feeding 만 적용하는 것은 모델 성능에 상당한 영향을 주지 않았음.
- 그러나, 높은 학습률 (Learning Rate) 과 결합했을 때, 모델 성능을 상당히 증가시켰음.
- Dense Re-feeding 없이 높은 학습률 (0.005) 만을 이용할 때, 모델은 분기 하기 (Diverge) 시작함.
- 세부사항은 Figure 5에 있음.

- Dense Re-feeding을 적용하고, Learning Rate을 증가시키는 것은 추정 RMSE를 0.9167 -> 0.9100으로 추가적인 향상을 제공했음.
- 가장 좋은 추정 RMSE를 가진 CheckPoint를 선택하고, \(test\) RMSE를 계산하여 0.9099를 얻었으며, 이는 다른 방법들보다 상당히 좋다고 믿는 수치임.
3.7 Comparison with Other Methods
- 우리가 사용한 데이터 (Table 1의 데이터 설명) 에 대해 PMF, T-SVD, I/U-AR 보다 성능이 좋다고 보여진 아래 접근법의 Recurrent Recommender Network와 가장 좋은 우리 모델을 비교함.
- T-SVD와 RRN과는 달리, 우리 방법은 등급의 시간적 역학 (Temporal Dynamics) 을 명시적으로 고려하지 않음.
- 그러나, Table 3은 \(future\) 등급 예측 작업에서 이러한 방법들보다 여전히 더 좋은 성능을 내는 것을 보여줌.
- 우리는 훈련 집합만을 사용하여 각 모델을 훈련하고, 100 Epoch에 대해 추정 RMSE를 계산함.
- 그런 다음, 가장 높은 추정 RMSE를 가진 Checkpoint에서 테스트 집합을 테스트함.
- "Netflix 3 months"는 "Netflix full"에 비해 훈련 데이터가 7배 더 적음.
- 따라서, 이 데이터에 대해서만 훈련하면 모델의 성능이 크게 떨어지는 것은 놀라운 일이 아님.
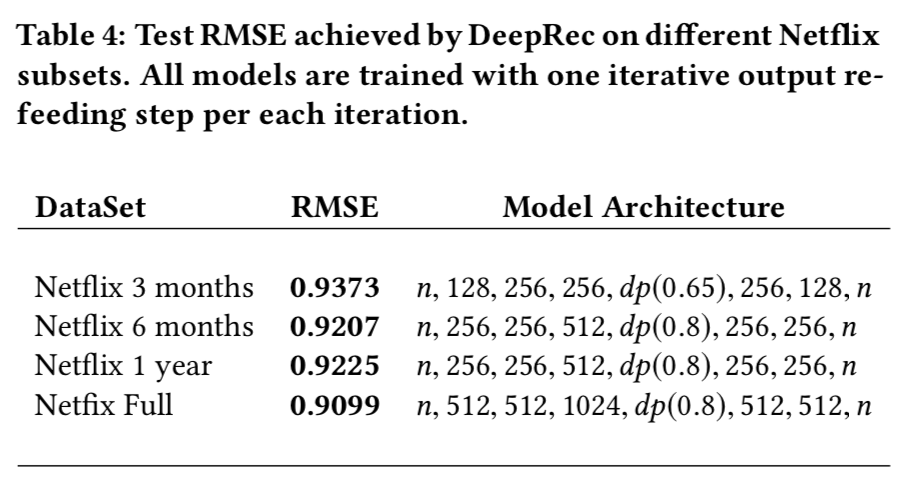
- 실제로, "Netflix full"에서 가장 좋은 성능을 보이는 모델도 이 집합에서는 Overfitting이 발생하며, 그래서 우리는 모델 복잡도를 감소시켜야 했음 (세부사항은 Table 4).
4. Conclusion
- 딥러닝은 머신러닝의 많은 영역에서 혁명을 일으켜왔으며, 추천 시스템에서도 마찬가지임.
- 이 논문에서는 잘 구축되고 (Dropout) 비교적 최근 ("Scaled Exponential Linear Units") 딥러닝 기법들을 사용하여 상대적으로 적은 양의 데이터임에도 불구하고 Deep Autoencoder가 얼마나 많이 성공적으로 훈련될 수 있는지를 증명했음.
- 게다가, 우리는 CF에서 Dense 갱신을 수행하는 기법인 \(Iterative Output Re-feeding\) 을 소개했으며, Learning Rate를 증가시켜서 모델의 일반화 성능을 추가로 향상시킴.
- \(future\) 등급 예측 작업에서, 우리 모델은 추가적인 시간적 신호를 사용하지 않고도 다른 접근보다 나은 성능을 발휘함.
- 우리 코드는 아이템 기반 모델 (ex. I-AutoRec) 을 지원하지만, 이 접근법이 유저 기반 모델 (ex. U-AutoRec) 보다 덜 실용적이라고 주장함.
- 이러한 이유는 실제 추천 시스템에서는 보통 아이템보다 사용자가 훨씬 더 많기 때문임.
- 결국, 개인화 추천 시스템을 구축하고 스케일링 문제에 직면했을 때, 아이템을 샘플링하는 것은 허용될 수 있지만 사용자는 그렇지 않음.
반응형
'Paper > Recommendation' 카테고리의 다른 글
| Session-based Recommendation with Graph Neural Networks (0) | 2020.03.28 |
|---|---|
| BPR: Bayesian Personalized Ranking from Implicit Feedback (1) | 2020.02.23 |
| Wide & Deep Learning for Recommender Systems (0) | 2020.01.19 |
| Item2Vec: Neural Item Embedding for Collaborative Filtering (2) | 2020.01.01 |
| Matrix Factorization Techniques for Recommender Systems (0) | 2019.12.14 |
댓글