
티스토리 뷰
반응형
원본 및 참조
- http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/
- http://karpathy.github.io/2015/05/21/rnn-effectiveness/
- https://wikidocs.net/22886
RNN (Recurrent Neural Network) ?
- 사람은 매번 생각을 처음부터 시작하지 않음. 당신이 이 에세이를 읽으면서, 이전 단어들에 대한 이해를 바탕으로 각 단어들을 이해함.
- 모든 것을 버리고 처음부터 다시 사고를 시작하는 것은 아님. 당신의 생각은 지속적이라는 것임.
- 기존 신경망들은 이러한 점을 할 수 없으며, 이 것은 중요한 결점인 것처럼 보임.
- 예를 들어, 당신은 영화에서 매 지점마다 어떤 종류의 사건이 일어나는지 분류하는 것을 상상함.
- 기존 신경망이 어떻게 영화의 이전 사건들을 사용하여 이후 사건들에 대한 추론을 할 수 있는지 명확하지 않음.
- RNN은 이러한 이슈를 다루며, 내부에 정보를 지속하는 루프로 구성된 네트워크임.
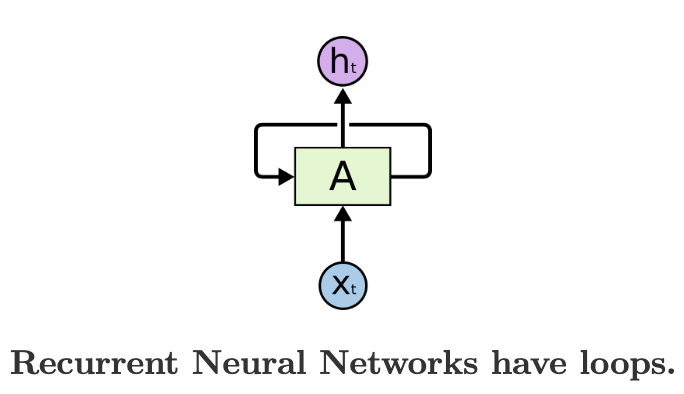
- 위 다이어그램에서, A는 신경망의 덩어리, X_t는 입력 (Input), h_t는 출력 (Output) 값으로 구성되어 있으며, 이 루프는 네트워크의 어떤 단계에서 다음 단계로 정보를 전달할 수 있게 해줌.
- 이러한 루프들은 RNN을 미스터리하게 보이도록 만듬. 그러나, 조금만 더 생각해 보면, 루프들은 일반적인 신경망과 크게 다르지 않다는 것임.
- RNN은 동일한 네트워크의 다중 복사본이라고 생각할 수 있으며, 각 네트워크는 메세지를 그 다음 후계자 네트워크에 전달함.
- 우리가 루프를 풀면 어떻게 되는지 고려해보겠음 :
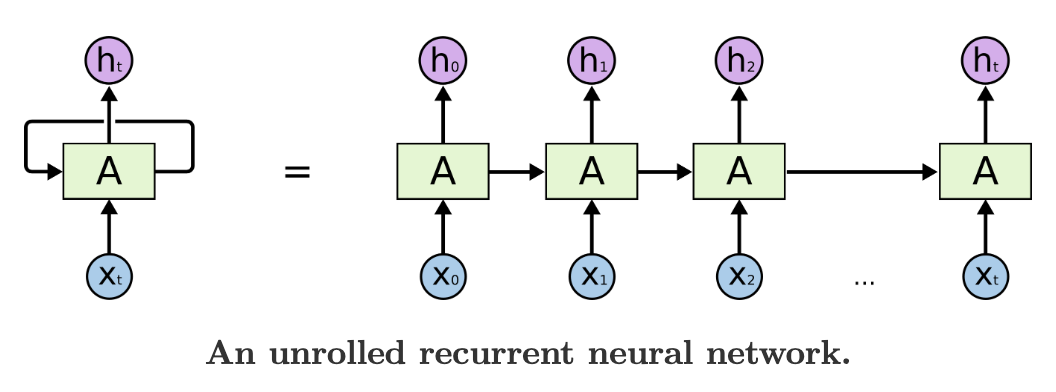
- 이 체인과 같은 속성은 RNN이 리스트와 시퀀스들과 밀접하게 연관되어 있음을 보여줌.
- 이 네트워크들은 그러한 연속적인 데이터에 사용하기 위한 신경망의 자연적인 아키텍처임.
- 지난 몇 년 동안, 다양한 문제들에서 RNN을 적용하는 것에 대해 믿을 수 없는 성공들이 있었음 : 음성 인식, 언어 모델링, 번역, 이미지 캡셔닝, ... 등등.
The Unreasonable Effectiveness of Recurrent Neural Networks
Sequences
- 당신의 배경에 따라 당신은 궁금해 할 수 있음 : 무엇이 RNN을 특별하게 만드는가?
- 바닐라 신경망 (및 CNN) 의 두드러진 한계는 API가 너무 제약되어 있다는 것임.
- 바닐라 ? - 바닐라 아이스크림이 가장 기본적인 맛을 가진 아이스크림이라고 하여 가장 단순한 형태의 RNN을 바닐라 RNN이라고 함.
- 이 네트워크들은 입력으로 (ex. 이미지) 고정 크기 벡터를 받아들이고 출력으로 (ex. 서로 다른 클래스들의 확률들) 고정 크기 벡터를 생산하는 것 뿐만이 아님 : 이러한 모델들은 고정된 양의 계산 단계들 (ex. 모델 계층 수) 을 사용하여 이 매핑을 수행함.
- RNN이 더 흥미로운 핵심 이유는 RNN이 벡터 시퀀스에 대해 다룰 수 있게 해주는 것임 : 입력, 출력, 또는 이 둘의 가장 일반적인 케이스 시퀀스들.
- 다음과 같은 몇 가지 예제가 이를 구체적으로 만들어 줌 :
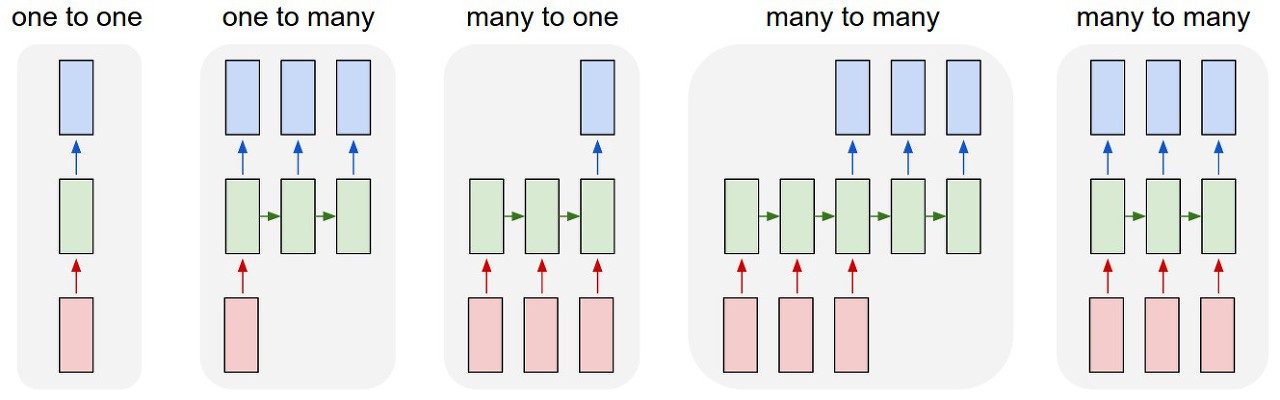
- 각각의 사각형은 벡터이며, 화살표는 함수를 나타냄 (ex. 행렬 곱셈). 입력 벡터들을 빨간색, 출력 벡터들은 파란색이며, 초록색 벡터는 RNN의 상태 (State) 를 유지함.
- 왼쪽에서 오른쪽으로 :
- RNN 없는 바닐라 모드, 고정 크기 입력에서 고정 크기 출력 (ex. 이미지 분류) 에 이르기까지.
- 출력 시퀀스 (ex. 이미지 캡셔닝은 이미지를 받고, 단어들의 문장을 출력함).
- 입력 시퀀스 (ex. 주어진 문장이 긍정 또는 부정 감정을 표현하는 것으로 분류되는 감성 분석).
- 입력, 출력 시퀀스 (ex. 기계 번역 : RNN이 영어 문장을 읽고, 그런 다음 불어 문장을 출력함).
- 동기화된 입력, 출력 시퀀스 (ex. 우리가 비디오의 각 프레임에 레이블링하고 싶은 비디오 분류).
반응형
'NLP (Natural Language Processing)' 카테고리의 다른 글
| NPLM (Neural Probabilistic Language Model) (2) | 2020.01.18 |
|---|---|
| LSTM (Long Short Term Memory) (0) | 2019.11.15 |
| Distributed Representation / Dense Vector (0) | 2019.03.28 |
댓글