단순한 문자열 검색
- 문자열 'ACBABCBABC' 에서 'ABC'를 찾는다고 해보자.
- 단순한 방법은 'ABC'를 한 칸씩 옮기면서 비교하는 것이다.
| A |
C |
B |
A |
B |
C |
B |
A |
B |
C |
| A |
B |
C |
|
|
|
|
|
|
|
-> 다르다.
| A |
C |
B |
A |
B |
C |
B |
A |
B |
C |
| |
A |
B |
C |
|
|
|
|
|
|
-> 다르다.
| A |
C |
B |
A |
B |
C |
B |
A |
B |
C |
| |
|
A |
B |
C |
|
|
|
|
|
-> 다르다.
| A |
C |
B |
A |
B |
C |
B |
A |
B |
C |
| |
|
|
A |
B |
C |
|
|
|
|
-> 같다.
| A |
C |
B |
A |
B |
C |
B |
A |
B |
C |
| |
|
|
|
A |
B |
C |
|
|
|
-> 다르다.
| A |
C |
B |
A |
B |
C |
B |
A |
B |
C |
| |
|
|
|
|
|
A |
B |
C |
|
-> 다르다.
| A |
C |
B |
A |
B |
C |
B |
A |
B |
C |
| |
|
|
|
|
|
|
A |
B |
C |
-> 같다.
- 문자열 끝까지 진행하며, 여기서는 문자열 패턴 'ABC'가 총 2번 등장하는 것을 알 수 있다.
- 하지만, 이 단순 비교는 문자열의 길이가 M이고 찾으려는 패턴의 길이가 N이라면 시간복잡도는 O(M * N) 을 갖게 되어 상당히 오래 걸린다.
- 이러한 문제를 해결하여 시간복잡도 O(M * N) 을 O(M + N)으로 줄일 수 있는 방법이 KMP 알고리즘이다.
KMP (Knuth–Morris–Pratt)
- KMP 이름은 알고리즘을 개발한 사람들의 이름 맨 앞글자를 따와서 만들어졌다.
- KMP의 과정을 간단히 얘기하면 문자열을 비교하다가 다르다면, 실패 함수를 통해 다음 번에 참조할 인덱스를 정해준다.
- 즉, 건너뛴다는 얘기가 된다.
(1) 접두사 (Prefix), 접미사 (Suffix)
- 문자열 'ABABAABA'가 있다고 했을 때, 접두사와 접미사는 아래와 같을 것이다.
| 접두사 (Prefix) |
접미사 (Suffix) |
| A |
A |
| AB |
BA |
| ABA |
ABA |
| ABAB |
AABA |
| ABABA |
BAABA |
| ABABAA |
ABAABA |
| ABABAAB |
BABAABA |
| ABABAABA |
ABABAABA |
(2) 실패 함수 (Failure Function) : pi 배열
- pi[X]는 주어진 문자열의 0 ~ X 까지의 부분 문자열 중 접두사와 접미사가 일치하는 가장 긴 길이이다.
- 위 문자열 'ABABAABA'에서 접두사와 접미사가 같은 최대 길이를 구해 저장해 놓는 배열이다.
| 인덱스 X |
문자열 (0 ~ X) |
길이 Pi[X] |
| 0 |
A |
0 |
| 1 |
AB |
0 |
| 2 |
ABA |
1 |
| 3 |
ABAB |
2 |
| 4 |
ABABA |
3 (절반이 넘는 경우에도 세어준다.) |
| 5 |
ABABAA |
1 |
| 6 |
ABABAAB |
2 |
| 7 |
ABABAABA |
3 |
Code
pi 배열 구하기
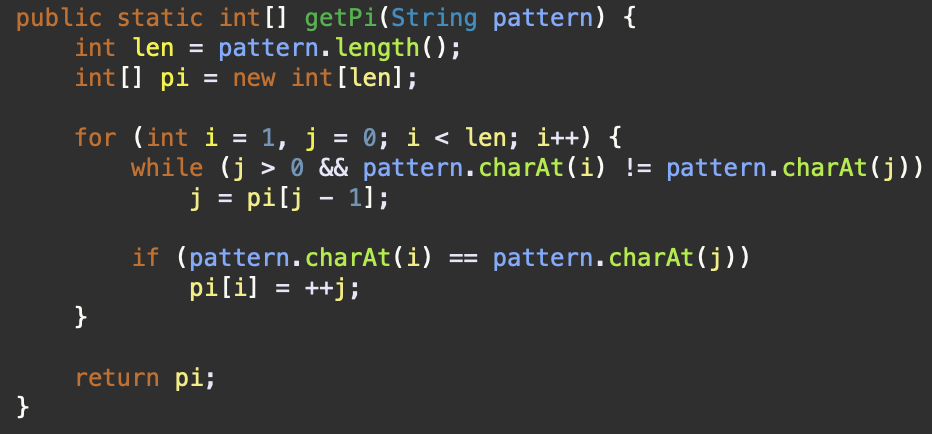
- 'ABABAABA'의 pi 배열을 구한다고 해보자.
- 처음 상태는 아래와 같다.
- j 위치의 문자 A와 i 위치의 문자 B는 같지 않다.
- 따라서 현재 i 위치 값을 0으로 집어넣고 i를 1 증가시킨다.
| j |
|
i |
|
|
|
|
|
| A |
B |
A |
B |
A |
A |
B |
A |
| 0 |
0 |
1 |
|
|
|
|
|
- 두 번째 경우 j와 i 위치 문자가 같으므로 j 위치 + 1인 값 (0 + 1 = 1) 을 집어넣는다.
- 그리고 중요한 점은 i 뿐만 아니라 j 도 1을 증가시킨다.
| |
j |
|
i |
|
|
|
|
| A |
B |
A |
B |
A |
A |
B |
A |
| 0 |
0 |
1 |
2 |
|
|
|
|
- 현재 j 위치 문자와 i 위치 문자가 동일하므로 마찬가지로 j 위치 + 1 값 (1 + 1 = 2) 을 넣어준다.
| |
|
j |
|
i |
|
|
|
| A |
B |
A |
B |
A |
A |
B |
A |
| 0 |
0 |
1 |
2 |
3 |
|
|
|
- 문자가 동일하므로 j 위치 + 1 값 (2 + 1 = 3) 을 넣어준다.
| |
|
|
j |
|
i |
|
|
| A |
B |
A |
B |
A |
A |
B |
A |
| 0 |
0 |
1 |
2 |
3 |
|
|
|
- 현재 j 위치 문자는 B이고 i 위치 문자는 A 이므로, 문자가 다르다.
- 여기서는 j의 이전 위치의 값 (1) 으로 이동한다.
- 즉, 인덱스 역할이 되며, j는 배열 1 위치로 이동한다.
| |
j |
|
|
|
i |
|
|
| A |
B |
A |
B |
A |
A |
B |
A |
| 0 |
0 |
1 |
2 |
3 |
|
|
|
- 인덱스 1로 이동한 j 위치의 문자 또한 현재 i 위치의 문자와 다르다.
- 따라서, 현재 j의 이전 인덱스의 값 (0) 을 인덱스로 사용하여 이동한다.
| j |
|
|
|
|
i |
|
|
| A |
B |
A |
B |
A |
A |
B |
A |
| 0 |
0 |
1 |
2 |
3 |
|
|
|
- 문자가 동일하므로 배열에 값 (0 + 1 = 1) 을 넣어주고, j와 i의 위치를 하나씩 앞으로 옮긴다.
| |
j |
|
|
|
|
i |
|
| A |
B |
A |
B |
A |
A |
B |
A |
| 0 |
0 |
1 |
2 |
3 |
1 |
|
|
- 마찬가지로 문자가 동일하므로 현재 j의 위치 1 + 1 = 2 값을 넣어준다.
- j와 i 모두 한 칸씩 앞으로 전진한다.
| |
|
j |
|
|
|
|
i |
| A |
B |
A |
B |
A |
A |
B |
A |
| 0 |
0 |
1 |
2 |
3 |
1 |
2 |
|
- 위와 동일하게 j 위치인 2에 + 1을 한 3 값을 i 위치에 넣어준다.
- j와 i 모두 앞으로 한 칸씩 전진하게 될텐데, i가 문자열 길이보다 커지므로 과정이 종료되고 최종 pi 배열이 만들어진다.
| 0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| A |
B |
A |
B |
A |
A |
B |
A |
| 0 |
0 |
1 |
2 |
3 |
1 |
2 |
3 |
KMP 함수 구현
- KMP 함수 또한 pi 배열 코드와 비슷하게 동작한다.
- 단, 차이점은 문자가 동일하고 j가 패턴의 끝부분인 경우, pi[j]의 값으로 j를 갱신한다는 것이다.

- 문자열 'ABABAABA'에서 문자열 'ABA'의 패턴을 찾는다고 하자.
- 그러면 찾을 패턴 문자열 'ABA'에 대한 pi배열을 만들어야 하며, 아래와 같을 것이다.
- 패턴의 이동은 i와 j를 동일한 위치 선상에 맞춘 것이다.
- why 동일 위치?) 항상 현재 i와 j 인덱스 문자를 비교하기 때문에.
| |
|
i |
|
|
|
|
|
| 0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| A |
B |
A |
B |
A |
A |
B |
A |
| A |
B |
A |
|
|
|
|
|
| 0 |
1 |
2 |
|
|
|
|
|
| |
|
j |
|
|
|
|
|
- 0 ~ 2까지 i와 j 문자는 모두 동일하므로 한칸씩 계속해서 전진한다.
- 문자가 동일하면서 j의 위치가 패턴의 끝부분이라면, 모두 찾았다는 얘기이므로 pi[2] (현재 j 인덱스 : 2) = 1로 j를 갱신하고 패턴 문자열을 점프한다. pi[2] 만큼 점프한다는 것이 아니다.
- 그런 다음, i는 1을 증가시킨다.
| |
|
|
i |
|
|
|
|
| 0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| A |
B |
A |
B |
A |
A |
B |
A |
| |
|
A |
B |
A |
|
|
|
| |
|
0 |
1 |
2 |
|
|
|
| |
|
|
j |
|
|
|
|
- 현재 i (3) 와 j (1) 인덱스 부터 문자열 비교를 다시 시작한다.
| |
|
|
|
i |
|
|
|
| 0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| A |
B |
A |
B |
A |
A |
B |
A |
| |
|
A |
B |
A |
|
|
|
| |
|
0 |
1 |
2 |
|
|
|
| |
|
|
|
j |
|
|
|
- 문자열 내에서 패턴 문자열을 모두 찾았으므로, 마찬가지로 pi[2] = 1 값으로 j를 갱신시키고, i를 1 증가시킨다.
| |
|
|
|
|
i |
|
|
| 0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| A |
B |
A |
B |
A |
A |
B |
A |
| |
|
|
|
A |
B |
A |
|
| |
|
|
|
0 |
1 |
2 |
|
| |
|
|
|
|
j |
|
|
- 현재 i와 j 인덱스 문자부터 다시 비교를 시작한다.
| |
|
|
|
|
i |
|
|
| 0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| A |
B |
A |
B |
A |
A |
B |
A |
| |
|
|
|
A |
B |
A |
|
| |
|
|
|
0 |
1 |
2 |
|
| |
|
|
|
|
j |
|
|
- 문자를 비교하고, 현재 i, j 인덱스 위치의 문자가 다른 것이 확인되었다.
- 그러면, 현재 j 인덱스 (1) 의 이전 위치 (0) 의 pi배열 값 (pi[0] = 0) 으로 j를 갱신한다.
| |
|
|
|
|
i |
|
|
| 0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| A |
B |
A |
B |
A |
A |
B |
A |
| |
|
|
|
|
A |
B |
A |
| |
|
|
|
|
0 |
1 |
2 |
| |
|
|
|
|
j |
|
|
- 비교하려는 문자열 인덱스 i는 그대로 유지한다.
- 그리고 패턴 인덱스인 j를 pi 배열을 통해 1에서 0으로 갱신하고, 다시 i와 j번째 인덱스 문자 부터 비교한다.
| |
|
|
|
|
|
|
i |
| 0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| A |
B |
A |
B |
A |
A |
B |
A |
| |
|
|
|
|
A |
B |
A |
| |
|
|
|
|
0 |
1 |
2 |
| |
|
|
|
|
|
|
j |
- 문자열에서 패턴을 찾았으므로, j를 pi[2]의 값으로 갱신하고, i를 1증가시킨다.
- 그런데 i가 문자열 인덱스의 범위를 벗어나기 때문에 알고리즘을 종료한다.
Reference
