

티스토리 뷰
반응형
플로이드 와샬(Floyd Warshall) ?
- 모든 쌍 간의 최단 거리를 구하고 싶다면 다익스트라, 벨만-포드 알고리즘보다 좀더 빠르고 간단한 플로이드 (Floyd) 의 모든 쌍 최단 거리 알고리즘을 사용하면 된다.
- 플로이드 알고리즘은 그래프의 모든 정점 쌍의 최단 거리를 저장하는 2차원 배열 dist[][] 를 계산한다.
- 이 배열의 원소 dist[u][v] 는 정점 u에서 v로 가는 최단 거리를 나타낸다.
정점의 경유점들
- 플로이드 알고리즘의 동작 과정을 이해하기 위해서는 경로의 경유점의 개념을 소개할 필요가 있다.
- 두 정점 u, v를 잇는 어떤 경로가 있다고 하자.
- 당연하지만 이 경로는 항상 시작점 u와 끝점 v를 지난다.
- 이 외에 이 경로는 다른 정점들을 지나쳐 갈 수도 있다.
- u와 v를 직접 연결하는 간선이 없거나, 다른 정점을 경유해서 가는 편이 전체 경로가 더 짧아지기 때문이다.
- 이와 같이 경로가 거쳐가는 정점들을 경유점이라고 하자.
- 정점 집합 S에 포함된 정점만을 경유점으로 사용해 u에서 v로 가는 최단 경로의 길이를 \(D_{s} (u, v)\) 라고 표기하자.
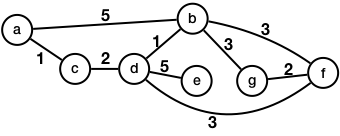
- 예를 들어, 아래 그림의 그래프에서 \(D_{[]}(a, b) = 5\) 이지만 \(D_{[c, d]}(a, b) = 4\) 이다.
- S의 모든 정점을 경유점으로 사용할 필요는 없다고 하자.
- 따라서, \(D_{[a, c, d, e, g, f]} (b, f) = D_{[]} (b, f) = 3\) 이다.
- 이 표기법을 쓸때 우리가 최종적으로 계산하고 싶은 값은 전체 정점의 집합 V를 모두 경유점으로 쓸 수 있는 \(D_{V}(u, v)\) 이고, 두 정점 사이를 잇는 간선 중 가장 짧은 간선의 길이 w(u, v) 는 \(D_{[]} (u, v)\) 가 된다는 사실을 알 수 있다.
- S에 포함된 정점만을 경유점으로 사용해 u에서 v로 가는 최단 경로를 알고 있다고 하자.
- S 중에 정점을 하나 골라 x라고 하면, 최단 경로는 x를 경유할 수도 있고 경유하지 않을 수도 있다.
각 경우에 최단 경로는 어떤 형태를 가질까?
- 경로가 x를 경유하지 않는다 :
- 이 경로는 S - {x} 에 포함된 정점들만을 경유점으로 사용한다.
- 경로가 x를 경유한다 :
- 이 경로를 u에서 x로 가는 구간과 x에서 v로 가는 구간으로 나눌 수 있다.
- 이 두 개의 부분 경로들은 각각 u와 x, x와 v를 잇는 최단 경로들이어야 한다.
- 당연하게도 두 개의 부분 경로들은 x를 경유하지 않으며, 따라서 S - {x}에 포함된 정점들만을 경유점으로 사용한다.
- S를 경유점으로 사용해 u에서 v로 가는 최단 경로는 위 두 가지 중 더 짧은 경로가 될 것이다.
- 따라서 \(D_{s} (u, v)\) 를 다음과 같이 재귀적으로 정의할 수 있다.
$$D_{s} (u, v) = \mathrm{min} \begin{cases} D_{S-{\{x\}}} (u, x) + D_{S-{\{x\}}} (x, v) \\ D_{S-{\{x\}}} (u, v) \end{cases}$$
플로이드 알고리즘의 프로토타입
- 앞의 점화식을 살짝 고치면 모든 쌍에 대한 최단 거리 문제를 동적 계획법으로 풀 수 있다.
- \(S_{k} = {0, 1, 2, \cdots, k}\) 라고 두고, \(C_{k} = D_{S_{k}}\) 라고 하자.
- 그러면 \(C_{k} (u, v)\) 는 0번 정점부터 k번 정점까지만을 경유점으로 썼을 때 u에서 v까지 가는 최단 경로의 길이가 된다.
- 이 표기를 사용하면 앞의 점화식을 다음과 같이 고쳐 쓸 수 있다.
$$C_{k} (u, v) = min \begin{cases} C_{k - 1} (u, k) + C_{k - 1} (k, v) \\ C_{k - 1} (u, v) \end{cases}$$
- 이 점화식에서 \(C_{k}\) 의 모든 값은 \(C_{k - 1}\) 에만 의존하기 때문에, 반복적 동적 계획법을 이용하면 쉽게 풀 수 있다.
- 이것을 구현한 것이 아래 코드이다.
- 이 코드에서 \(C_{k} (u, v)\) 의 값은 \(C[k][u][v]\) 에 저장된다.
- 따라서 함수의 종료 후에 u에서 v로 가는 최단 거리를 알려면 \(C[V - 1][u][v]\) 를 보면 된다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public static void Floyd_Proto() {
for (int i = 1; i <= V; i++) {
for (int j = 1; j <= V; j++) {
if (i != j)
C[0][i][j] = Math.min(graph[i][j], graph[i][0] + graph[0][j]);
else
C[0][i][j] = 0;
}
}
for (int k = 2; k <= V; k++) {
for (int i = 1; i <= V; i++) {
for (int j = 1; j <= V; j++) {
C[k][i][j] = Math.min(C[k - 1][i][j], C[k - 1][i][k] + C[k - 1][k][j]);
}
}
}
}
|
cs |
- 인접 행렬 표현에서 두 정점 사이에 간선이 없는 경우 아주 큰 값을 넣어 둔다는 점을 눈여겨보자.
- 이 큰 값은 실제로 존재하는 어떤 경로의 길이보다도 커야 한다.
- 이렇게 하면 경로가 존재하지 않는 경우를 따로 처리하지 않아도 된다.
- 마지막에 \(C[V-1][u][v]\) 가 아주 큰 값 이상이라면 경로가 존재하지 않음을 알 수 있다.
- 또 하나 눈여겨볼 것은 C[0]을 계산할 때 C[0][u][u]는 항상 0으로 초기화한다는 점이다.
- 자기 자신으로 가는 간선이 따로 없더라도 최단 거리는 항상 0이기 때문이다.
- 이 알고리즘의 시간 복잡도는 3중 for문이 지배한다.
- 각각은 \(O(|V|)\) 번 수행되기 때문에 전체 시간 복잡도는 \(O(|V|^{3})\) 이 된다.
메모리 사용량 줄이기
- 이 알고리즘은 대부분의 경우 \(|V|\) 번 다익스트라나 벨만-포드 알고리즘을 수행하는 것보다 효율적이다.
- 구현도 굉장히 간단하고, 반복문 내부가 단순하기 때문에 수행 속도도 빠르다.
- 위 코드에서 사실 문제가 되는 것은 시간 복잡도보다는 메모리 사용량이다.
- 예를 들어 \(|V|\) = 1000이라고 해보자.
- 시간 복잡도가 \(O(|V|^{3})\) 인 알고리즘은 컴퓨터에서 충분히 10초안에 수행할 수 있다.
- 그러나 \(|V|^{3}\) 크기의 32비트 정수 배열은 4GB의 용량을 필요로 하는데, 이는 32비트 리눅스에서 프로세스가 사용할 수 잇는 주소 공간의 최대치인 3GB를 훌쩍 넘어간다.
- 다행히 슬라이딩 기법을 사용하면 이 코드가 사용하는 배열의 크기를 \(O(|V|^{2})\) 로 줄일 수 있다.
- \(C_{k}\) 의 답은 \(C_{k - 1}\) 만 있으면 계산할 수 있기 때문에 \(C_{k - 2}, C_{k -3}\) 등의 값은 계속 가지고 있을 필요가 없다.
- 이 점을 이용하면 위 코드의 배열 크기를 \(2 \times |V| \times |V|\) 로 줄일 수 있다.
- \(C_{k} (u, v)\) 의 값을 \(C_{k \% 2}[u][v]\) 에 저장하면 된다.
- 플로이드의 최단 거리 알고리즘은 여기서 더 나아간다.
- 별도의 배열을 사용하지 않고 그래프의 가중치를 담는 인접 행렬 위에서 곧장 이 점화식의 결과를 계산하는 것이다.
- 어떻게 이와 같은 일이 가능할까?
- 위 코드에서 사용했던 점화식을 보면 \(C_{k} (u, v)\) 를 계산하기 위해 필요한 값은 \(C_{k - 1} (u, k)\) 과 \(C_{k - 1} (k, v)\) 뿐임을 알 수 있다.
- 그런데 \(C_{k - 1} (u, k)\) 와 \(C_{k} (u, k)\) 는 얼마나 다를까?
- \(C_{k - 1} (u, k)\) = 시작점부터 k - 1번 정점까지를 경유점으로 이용해 u에서 k로 가는 최단 경로의 길이
- \(C_{k} (u, k)\) = 시작점부터 k번 정점까지를 경유점으로 이용해 u에서 k로 가는 최단 경로의 길이
- 출발점이나 도착점이 k번 정점일 때 사용 가능한 경유점의 목록에 k가 추가되는 것은 아무런 의미가 없다.
- '지하철역을 들러 63빌딩에 가는 최단 경로'와 '지하철역과 63빌딩을 들러 63빌딩에 가는 최단 경로'가 똑같은 것과 마찬가지이다.
- 따라서 \(C_{k - 1}\) 과 \(C_{k}\) 의 값을 구분하지 않고 섞어서 써도 됨을 알 수 있다.
- 그래서 \(C[k \% 2]\) 와 \(C[(k - 1) \% 2]\) 를 구분할 필요가 없으며, 이들을 한 개의 2차원 배열에 섞어 써도 된다.
- 별도의 배열 C를 아예 만들지 않고 인접행렬 graph에 최단 거리를 계산하는 플로이드 알고리즘의 구현을 아래 코드에서 볼 수 있다.
- 이 알고리즘의 시간 복잡도는 \(O(|V|^{3})\) 그대로이고, 공간 복잡도는 \(O(|V|^{2})\) 로 줄어들었음을 쉽게 알 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
|
public static void Floyd() {
for (int i = 1; i <= V; i++)
graph[i][i] = 0;
for (int via = 1; via <= V; via++) {
for (int from = 1; from <= V; from++) {
for (int to = 1; to <= V; to++)
graph[from][to] = Math.min(graph[from][to], graph[from][via] + graph[via][to]);
}
}
}
|
cs |
플로이드 알고리즘의 최적화
- 시간 복잡도를 바꾸지는 않지만 실제로 플로이드 알고리즘의 동작 시간이 시간 제한에 아슬아슬하게 걸릴 때 사용할 수 있는 최적화가 있다.
- 바로 두 번째 for문 바로 다음에 from에서 via로 가는 경로가 실제 있는지를 확인해 보는 것이다.
- 만약 from에서 via로 가는 경로가 없다면 to에 대한 for문은 수행할 필요가 없기 때문이다.
- 이와 같은 최적화는 실제로 그래프에 간선이 적을수록 효과가 있는데, 경우에 따라 10%에서 20%까지 수행 시간을 단축할 수 있다.
실제 경로 계산하기
- 플로이드 알고리즘은 최단 경로에 간선을 하나씩 추가해 가는 다익스트라나 벨만-포드 알고리즘과는 다른 방식으로 동작하기 때문에, 실제 경로를 계산하는 과정도 아주 다르다.
- 플로이드 알고리즘을 수행한 뒤 두 정점 사이의 최단 경로를 계산하기 위해서는 각 정점의 쌍 u, v에 대해 마지막으로 graph[u][v]를 갱신했을 때 사용했던 k의 값을 저장해 두면 된다.
- 이 정점의 번호를 w라고 하자.
- 이 정점을 경유하니까 graph[u][v]가 최소치가 되었다는 말은 u에서 v로 가는 최단 경로가 w를 지난다는 의미이다.
- 따라서 재귀 호출을 이용해 u에서 w로 가는 최단 경로를 찾고, w에서 v로 가는 최단 경로를 찾은 뒤 이 둘을 합치면 u에서 v로 가는 최단 경로를 얻을 수 있다.
- 아래 코드는 최단 경로를 계산하는 데 필요한 정보를 부가적으로 계산하는 플로이드 알고리즘과 실제 최단 경로를 계산하는 함수의 구현을 보여준다.
- 추가 \(O(|V|^{2})\) 의 메모리만을 사용해서 최단 경로를 계산하는 것을 볼 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
public static void Floyd2() {
for (int i = 1; i <= V; i++)
graph[i][i] = 0;
for (int via = 1; via <= V; via++) {
for (int from = 1; from <= V; from++) {
for (int to = 1; to <= V; to++)
if (graph[from][to] > graph[from][via] + graph[via][to]) {
graph[from][to] = graph[from][via] + graph[via][to];
path[from][to] = via;
}
}
}
}
public static void Reconstruct(int u, int v, LinkedList<Integer> pathlist) {
if (path[u][v] != -1) {
pathlist.add(u);
if (u != v)
pathlist.add(v);
} else {
int w = path[u][v];
Reconstruct(u, w, pathlist);
pathlist.removeLast();
Reconstruct(w, v, pathlist);
}
}
|
cs |
도달 가능성 확인하기
- 플로이드 알고리즘의 또 다른 유명한 사용 예로 가중치 없는 그래프에서 각 정점 간의 도달 가능성 여부를 계산하는 것이 있다.
- 모든 정점 쌍 u, v에 대해 u에서 v로 가는 경로가 있는지를 확인하는 것이다.
- \(C_{k} (u, v)\) 의 정의를 0번부터 k번 정점가지를 경유점으로 썼을 때, u에서 v로 가는 경로가 있는지 여부를 나타내도록 변경하자.
- 그러면 다음과 같이 점화식이 성립한다.
$$C_{k} (u, v) = C_{k - 1} (u, v) \, || \, (C_{k - 1} (u, v) \, \&\& \, C_{k - 1} (k, v))$$
- 이것은 플로이드 알고리즘과 똑같지만, 최소치를 구하는 연산을 or 연산으로 바꾸고 덧셈 연산을 and 연산으로 바꾸는 차이밖에 없다.
- 이것은 시간 복잡도 면에서는 모든 정점에서 시작해서 BFS를 하는 방법보다 나을 것이 없지만, 플로이드 알고리즘의 간결한 구현 덕분에 자주 유용하게 쓰인다.
.
Reference
- 도서 : 프로그래밍 대회에서 배우는 알고리즘 문제 해결 전략
반응형
'Algorithm > Technique' 카테고리의 다른 글
| 최소 스패닝 트리 (MST, Minimum Spanning Tree) : 크루스칼 (Kruskal) (0) | 2019.12.10 |
|---|---|
| 소수 (Prime Number) & 에라토스테네스의 체 (Eratosthenes's Sieve) (0) | 2019.12.05 |
| KMP (Knuth–Morris–Pratt) (0) | 2019.11.26 |
| 벨만-포드 (Bellman-Ford) (0) | 2019.11.17 |
| DFS (Depth-First Search) & BFS (Breadth-First Search) (0) | 2019.10.08 |
댓글