
티스토리 뷰
반응형
Triplet Loss (wiki)
- Triplet loss는 baseline인 anchor를 positive, negative input들과 비교하는 인공 신경 네트워크에 대한 손실 함수 (loss function)임.
- anchor input과 positive input 사이의 거리는 최소화 되야하며, negative input과의 거리는 최대가 되야함.
- 보통 워드 임베딩 (word embeddings), 심지어는 벡터, 행렬 학습과 같은 임베딩 학습의 목적으로 유사성을 학습하는 데 사용됨.
- 이 손실 함수는 유클리디안 거리 (Euclidean distance) 함수를 사용하여 설명할 수 있음.

- A : anchor input.
- P : A와 동일한 클래스의 positive input.
- N : A와 다른 클래스인 negative input.
- α : positive와 negative 쌍 사이의 margin (여백).
- f : 임베딩 (embedding).
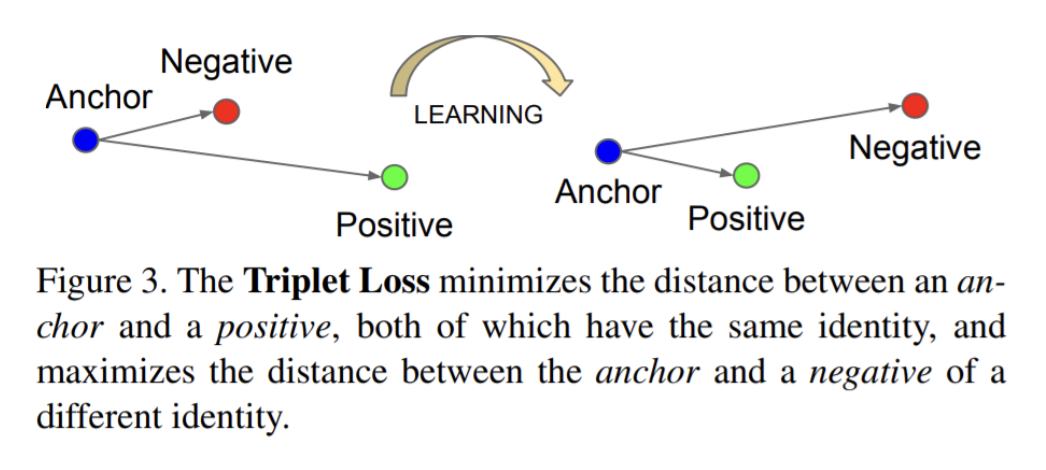
Triplet Loss (facenet)
- 임베딩은 아래와 같이 표현할 수 있음.
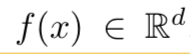
- d-차원의 유클리디안 공간에 이미지 x를 임베딩 한다는 뜻임.
- 추가적으로, 우리는 이 임베딩 한 것을 d-차원의 hypersphere (3차원보다 큰 차원으로 확장한 것) 에 거주하도록 아래 예시처럼 제한함.
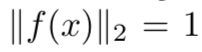
- 이 loss는 문맥의 근접이웃 분류 (context of nearest-neighbor classification) 에서 영감을 받음.
- 우리는 특정한 사람의 이미지 x(ai, anchor) 가 다른 사람의 이미지 x(ni, negative) 보다 동일한 사람의 모든 다른 이미지들 x(pi, positive) 과 더 가깝게 되도록 원함.

- α는 positive와 negative 쌍 사이에 적용된 margin임.
- T는 훈련 집합에서 모든 가능한 triplet의 집합이며, cardinality N을 가지고 있음.
- 최소화되는 손실 L은 다음과 같음.
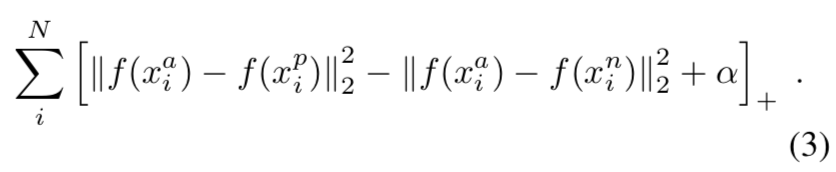
- 가능한 모든 triplet을 생성하는 것은 쉽게 만족하는 많은 triplet을 만들 수 있음. (식 1.의 제한을 수행하는)
- 이러한 triplet들은 훈련에 기여하지 않으며, 네트워크를 통과할 때 더 느린 수렴을 야기함.
- active하고 모델 개선에 기여할 수 있는 단단한 triplet을 선택하는 것이 중요함.
Triplet Selection
- 빠른 수렴을 보장하기 위해서 식 1에서 triplet 제한을 위반하는 triplet을 선택하는 것은 중요함.
- 이 것이 의미하는 것은 x(ai) 가 주어졌을 때, 우리는 x(pi, hard positive) 가 (1), 그리고 유사하게 x(ni, hard negative) 가 (2) 처럼 선택되는 것을 요구함.
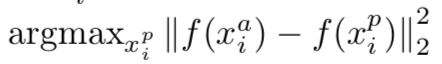

- 전체 훈련 집합에서 argmin과 argmax를 계산하는 것은 불가능함. 추가적으로, 잘못 레이블되고 미흡하게 이미지화된 얼굴들이 hard positive와 negative를 지배하기 때문에 훈련이 제대로 안될 수 있음.
- 이러한 사고를 피하기 위한 두 가지 분명한 선택들이 있음.
- 가장 최근 네트워크 체크포인트를 사용하고 데이터 부분집합에서 argmin과 argmax를 계산하여 매 n번 단계마다 triplet offline을 생성함.
- triplet online을 생성함. 이 것은 mini-batch 내에서 hard positive / negative exemplars를 선택함으로써 행해질 수 있음.
- 여기서 우리는 online 생성에 초점을 맞추고 수천 개의 examplar의 순서로 커다란 mini-batches를 사용하고 mini-batch 내에서만 argmin과 argmax를 계산함.
- anchor와 positive 거리를 의미있게 표현하기 위해, 어느 하나의 신원에 대한 최소한의 exemplar가 각 mini-batch에 존재하도록 보장해야함.
- 연구에서 우리는 mini-batch별 약 40개 얼굴의 신원이 선택되도록 훈련 데이터를 샘플함.
- 추가적으로, 무작위로 샘플된 negative 얼굴들도 각 mini-batch에 추가됨.
- 가장 hard한 positive를 고르는 것 대신에, 우리는 mini-batch내 모든 anchor-positive 쌍을 사용하면서 hard negative를 선택함.
- 우리는 mini-batch 내 모든 anchor-positive 쌍과 hard anchor-positive 쌍을 나란히 비교하지는 않지만, 실제로 모든 anchor-positive 생성 방법이 더 견고하고 훈련을 시작하는데 있어서 약간 더 빠른 속도로 수렴된다는 것을 발견했음.
- 또한, 우리는 online 생성과 함께 triplet의 offline을 생성 하는 방법을 연구했고 작은 배치 사이즈를 사용할 수는 있지만 실험은 결정적이지 않았음.
- 가장 hard한 negative를 선택하는 것은 실제로 훈련 초기에 나쁜 로컬 미니마 (local minima) 로 이어질 수 있으며, 특히 충돌된 모델을 야기할 수 있음. (ex. f(x) = 0)
- 이를 완화하기 위해서, 아래와 같은 x(ni)를 선택하는 것이 도움이 됨.

- 우리는 이러한 negative exemplars를 semi-hard라고 부르며, 이 semi-hard는 anchor에서 positive exemplar 보다 더 멀리 떨어져 있지만, 여전히 제곱된 거리가 anchor-positive 거리에 가깝기 때문에 어려움.
- 그러한 negatives는 여백 (margin) α안에 있음. 언급한 것과 같이, 정확한 triplet 선택은 빠른 수렴을 위해 중요함.
- 한편으로 우리는 확률적 경사 하강법 (SGD, Stochastic Gradient Descent) 동안 수렴을 향상시키는 경향이 있으므로 작은 mini-batch를 사용하고자 함.
- 반면에, 구현 세부 사항을 통해 수십에서 수백개의 표본을 보다 효율적으로 배치 할 수 있음.
- 그러나, 배치 사이즈 관점에서 주요 제한은 우리가 mini-batch내에서 hard와 관련된 triplet을 선택하는 방법임.
- 대부분의 연구에서 우리는 약 1800개의 exemplar의 배치 사이즈를 사용함.
반응형
'Paper > Vision' 카테고리의 다른 글
| Image Question Answering using Convolutional Neural Network with Dynamic Parameter Prediction (0) | 2019.11.11 |
|---|---|
| Searching for MobileNetV3 (2) | 2019.10.09 |
| ArcFace: Additive Angular Margin Loss for Deep Face Recognition (1) | 2019.10.09 |
| AlexNet (0) | 2019.03.29 |
댓글