
티스토리 뷰
반응형
- 예시 데이터는 dplyr 패키지에 있는 'starwars' 데이터를 이용한다.

- 데이터 구조를 보자.
- 구조를 한 눈에 보기 위해서 일부 열들을 제거한다.
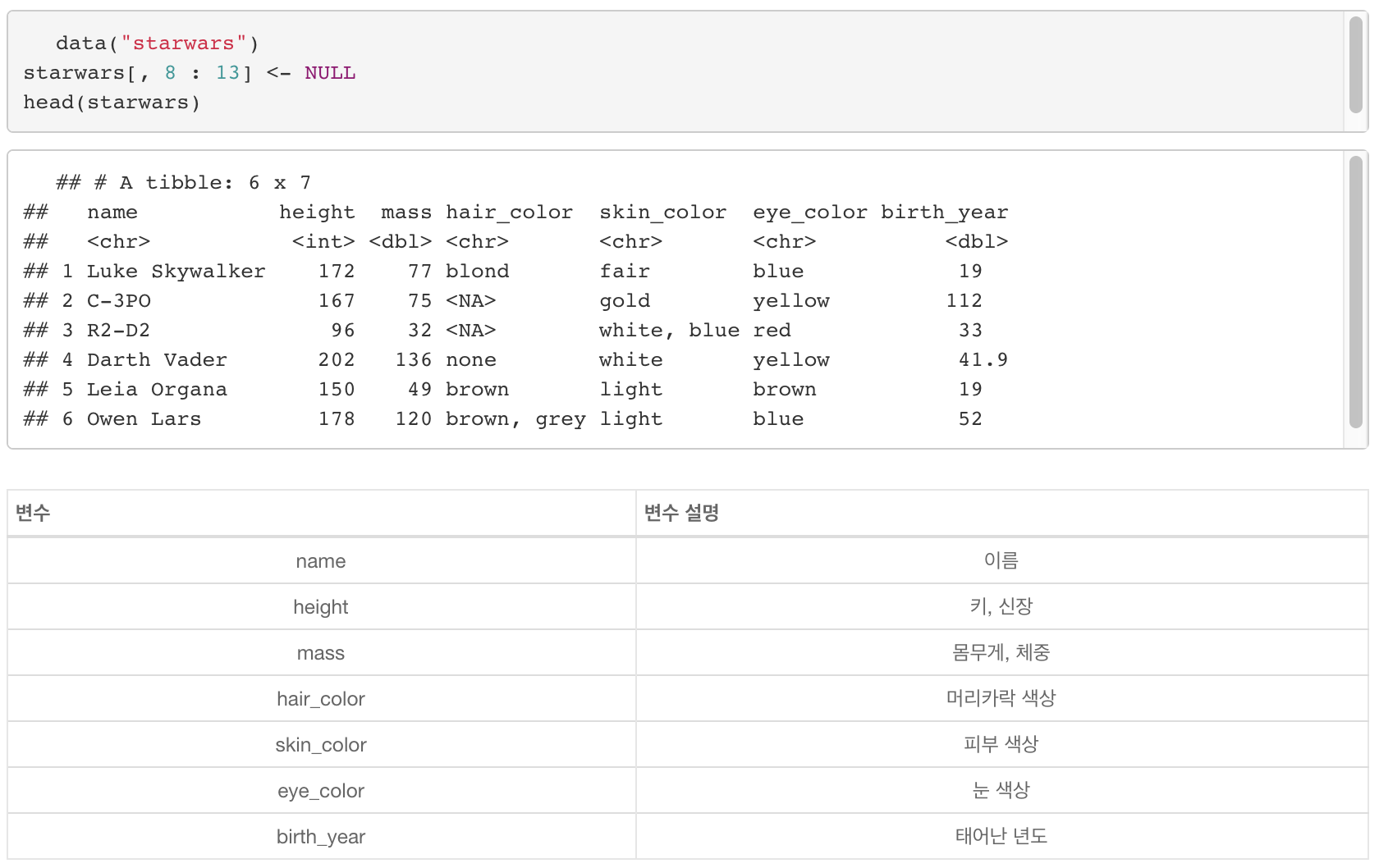
1. pull(데이터, 추출할 column)
- 선택한 column의 값들을 vector로 반환해준다.

2. select(데이터, 추출할 column)
- pull과 기능은 비슷하다.
- 차이점은 반환하는 데이터 형태로 select는 data.frame으로 반환한다.

3. pull과 select와 함께 쓰면 좋은 함수들
3-1. starts_with(문자열), ends_with(문자열)
- starts_with는 paramter로 전달한 문자열로 시작하는 column들을 반환한다.
- ends_with는 start_with와 반대로 parameter 문자열로 끝나는 column들을 반환한다.

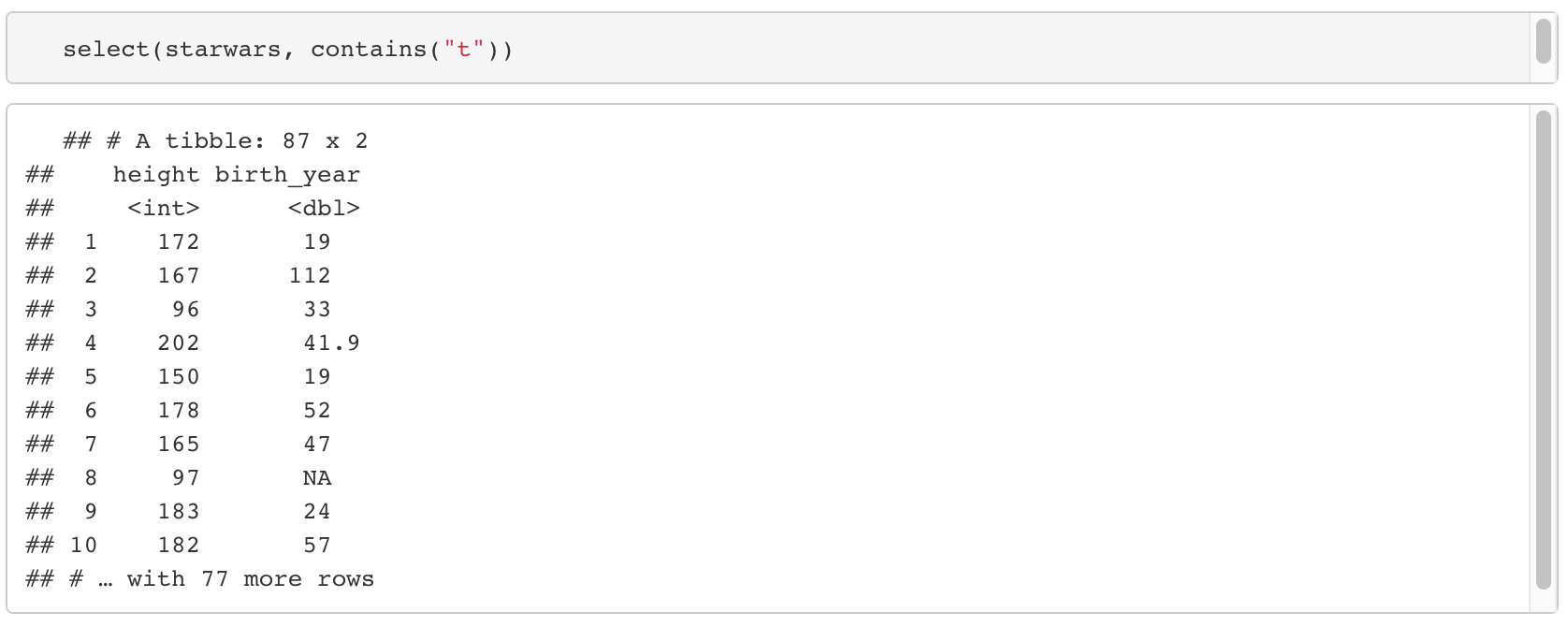
3-2. contains(문자열)
- 문자열의 위치는 상관없이 문자열을 포함하는 column들을 반환한다.
4. filter(데이터, 조건식)
- 조건식에 맞는 column이 아닌 Row 들을 반환한다.

5. distinct(데이터, column 이름)
- 해당 column 데이터에서 중복을 제외한 값들을 data.frame형태로 반환한다.

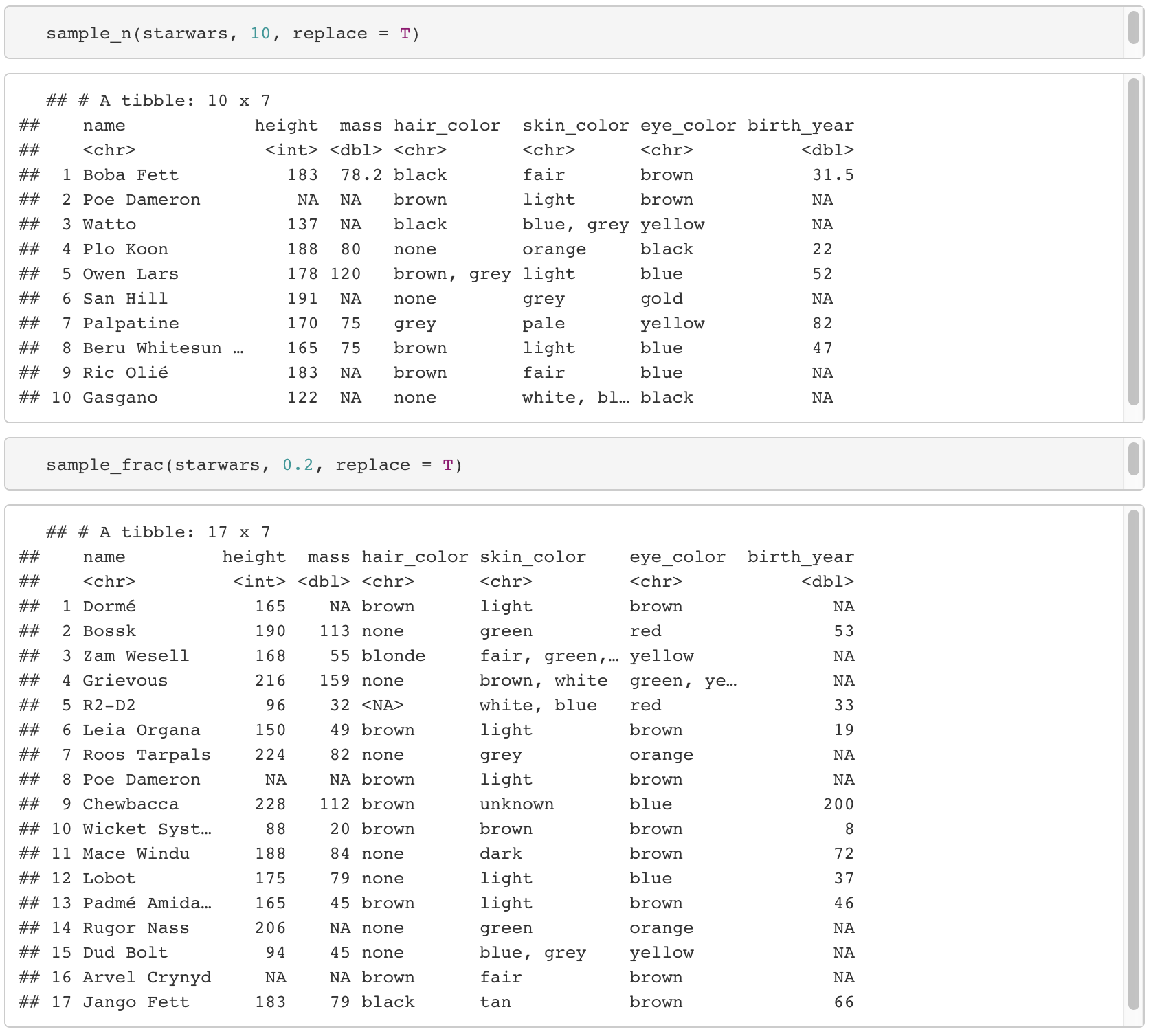
6. sample_n(data.frame, size, replace = F) / sample_frac(data.frame, size, replace = F)
- data.frame에서 size만큼 row데이터를 랜덤하게 추출한다. _n은 size 갯수만큼, _frac은 size 비율만큼 추출한다.
- replace는 복원 유무이며, replace = T라면 복원추출로 시행하며, F라면 비복원추출로 시행한다.
- 복원추출 : 간단하게 요약하자면 선택된 행이 중복으로 다시 선택될 수도 있다는 것.
7. slice(데이터, 범위)
- 범위에 해당하는 index의 row를 반환한다.

8. top_n(데이터, 갯수, 기준 column)
- 기준 column을 중심으로 column 값이 가장 높은 순부터 입력한 갯수만큼 row를 추출한다.

9. arrange(데이터, 정렬할 기준 column)
- 기준 column으로 row들을 정렬한다.
- column 이름을 그대로 쓰면 오름차순, desc(column)으로 쓰면 내림차순이다.

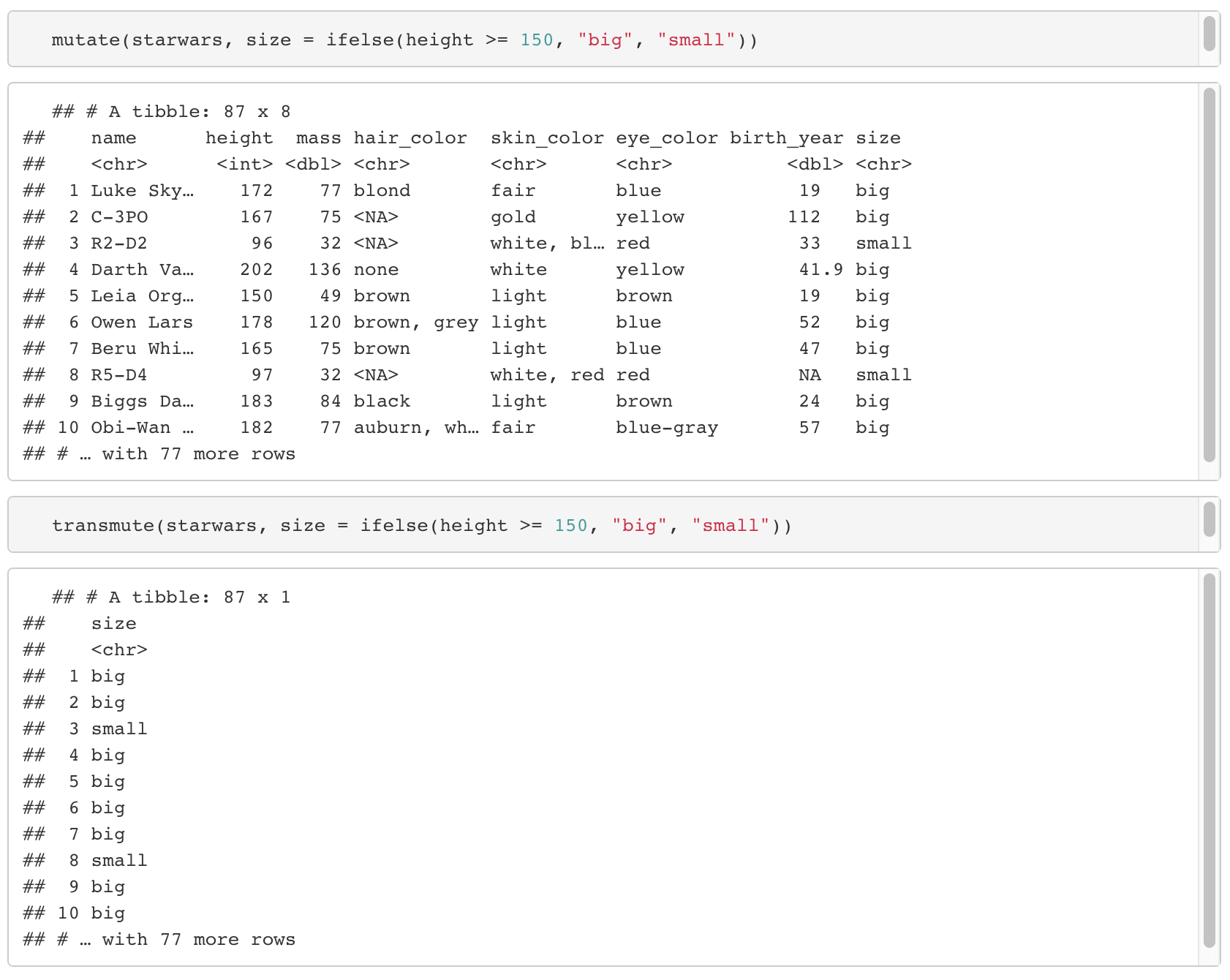
10. mutate(데이터, 새로운 column = 식) / transmute(데이터, 새로운 column = 식)
- 식을 통해서 새로운 column을 만든다. 단, mutate는 기존 데이터에 추가하고, transmute는 새로 만든 column만 반환한다.
11. summarise(데이터, 새로운 column = 식)
- 보통 group_by와 함께 사용하며, 데이터 값들을 요약해준다.

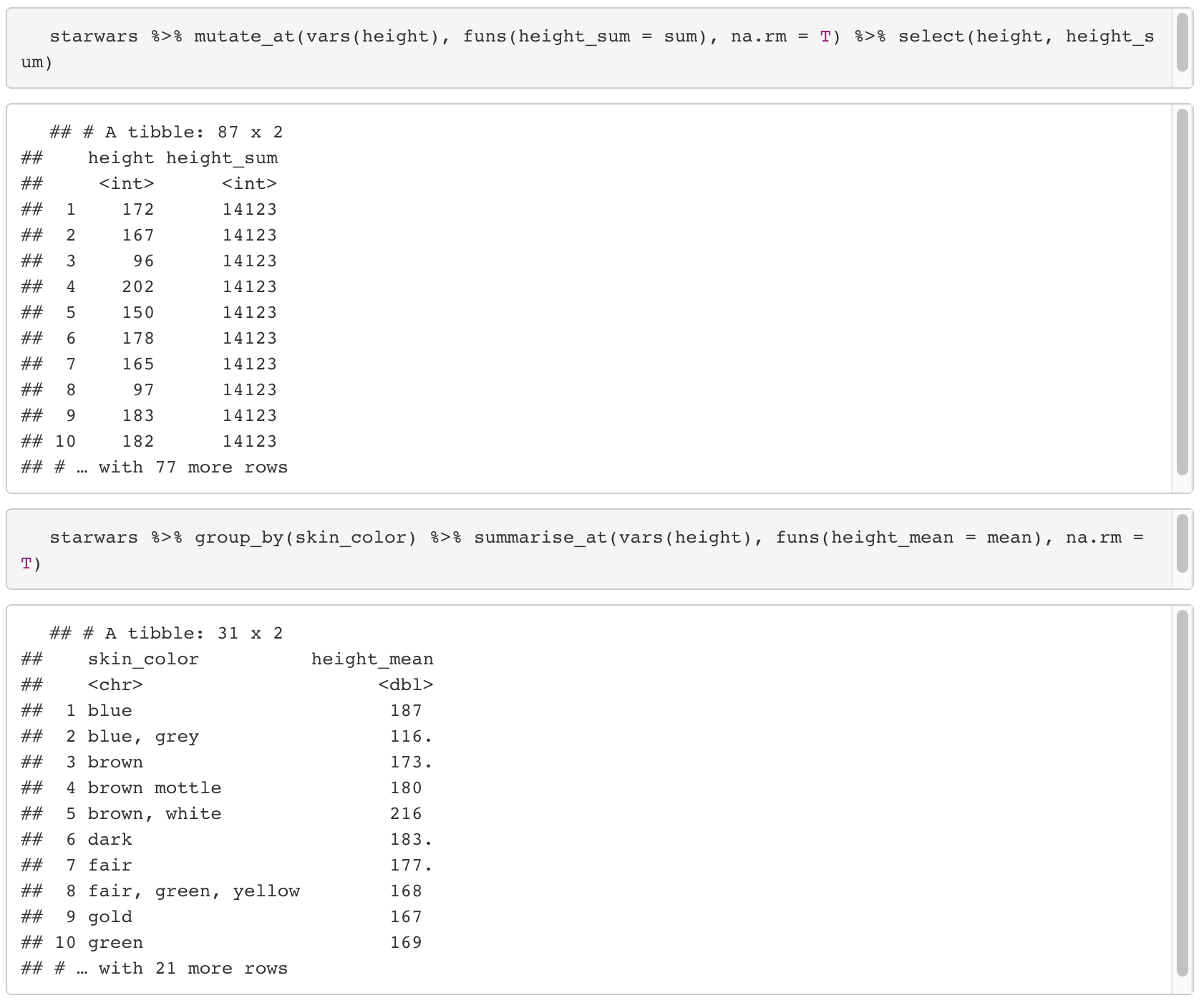
12. _at(data.frame, vars(column), 함수, na.rm = F) / _if(data.frame, 조건식, 함수) / _all(data.frame, 함수)
- mutate와 summarise는 세 종류 함수를 사용할 수 있다.
12-1. _at : 특정 column에 함수를 적용한다. column parameter를 넣어줄 때 vars()로 감싸줘야 한다.
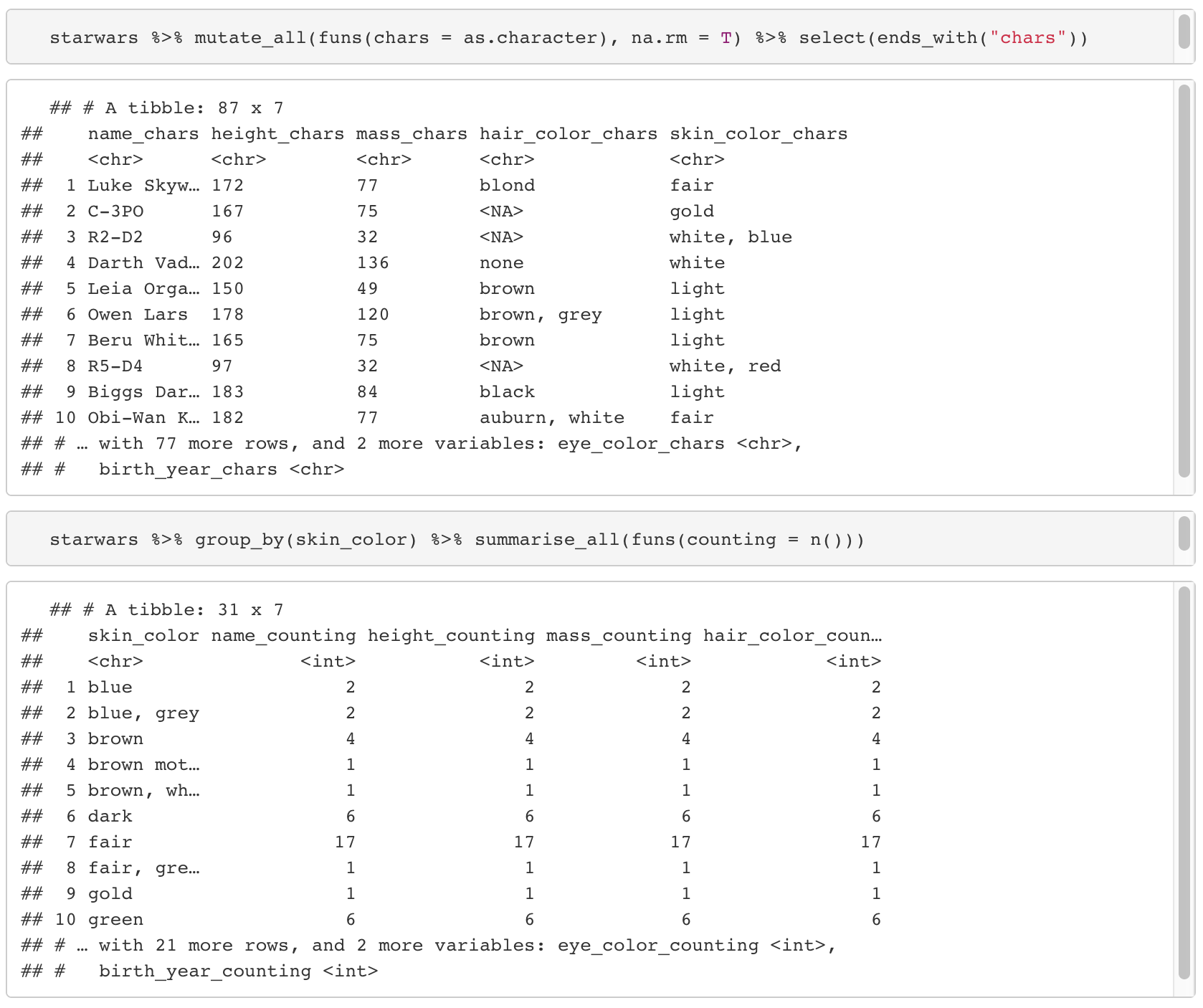
12-2. _if : 조건 식에 해당하는 column에 함수를 적용한다.

12-3. _all : 모든 column에 함수를 적용한다.
13. rename(데이터, 새 column 이름 = 기존 column)
- column이름을 바꿔준다.

14. group_by(데이터, column) / ungroup(데이터)
- 데이터를 column으로 그룹화해준다. ungroup은 그룹을 해제한다.
- ungroup은 거의 사용해본적이 없다.

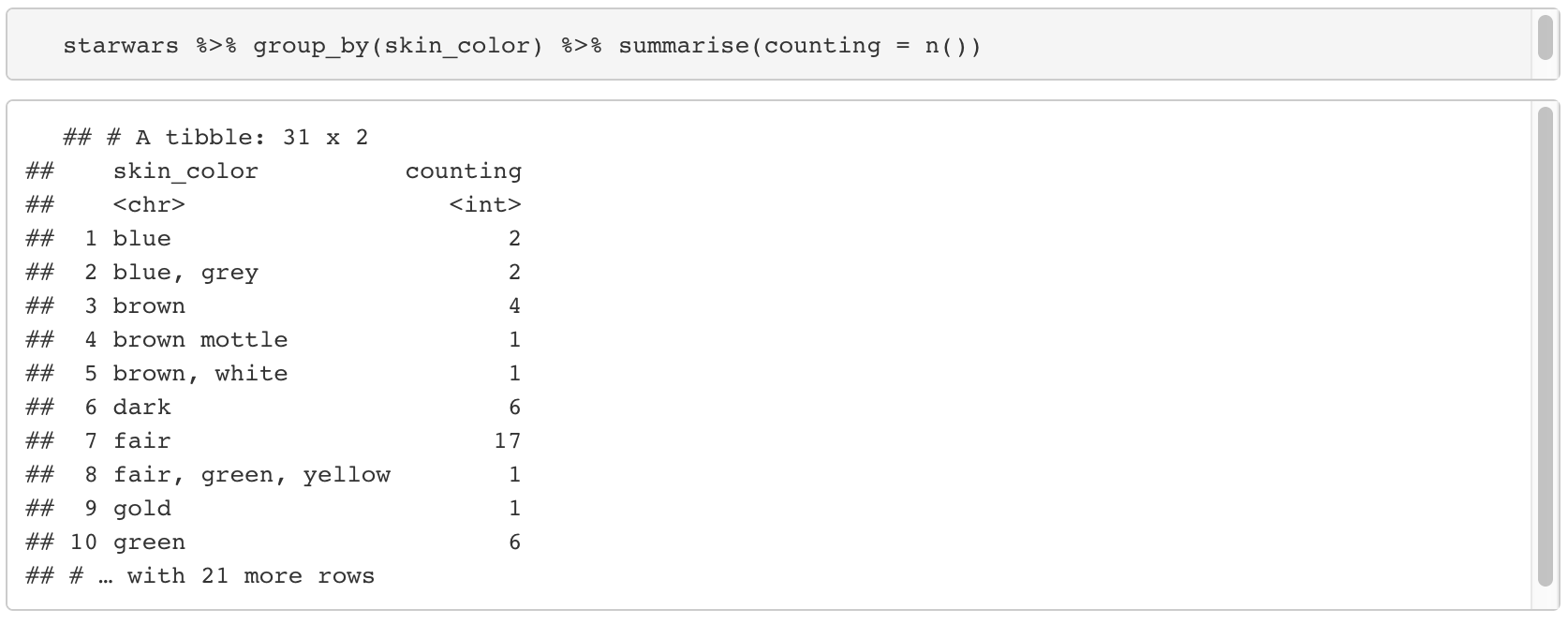
15. Summary Function
15-1. n() : 그룹화 후 총 갯수를 반환한다.
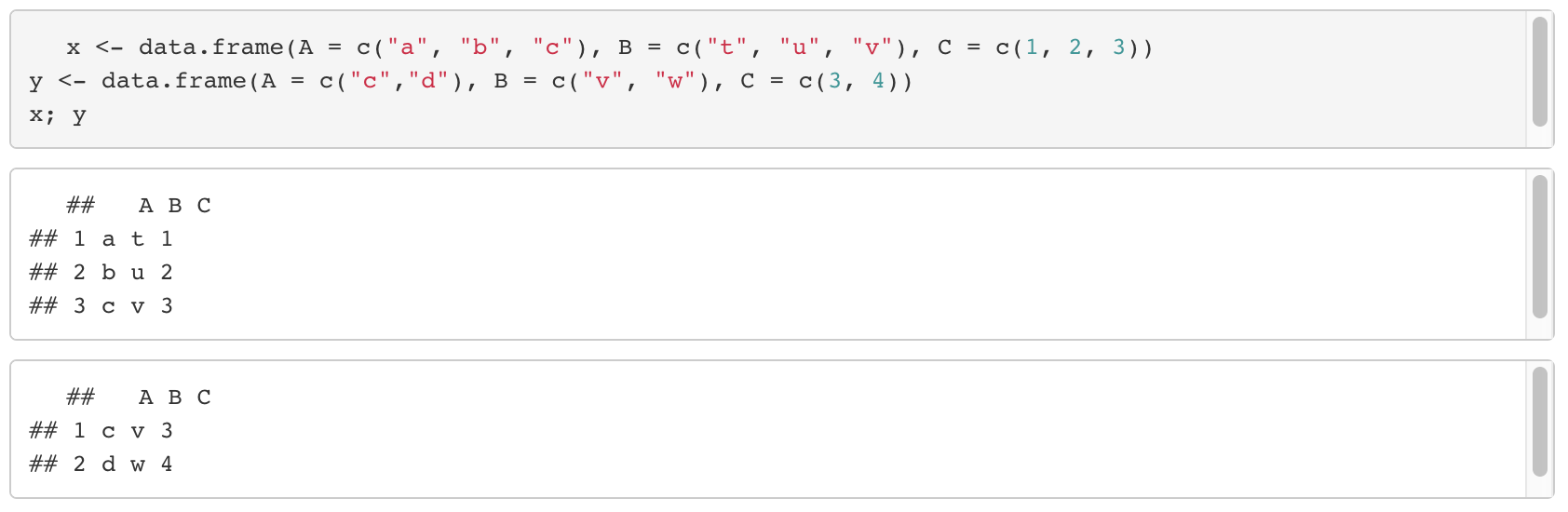
16. Set Function
- 흔히 알고 있는 집합 함수들이다.
- 집합에 대한 예시 데이터를 생성한다.
16-1. intersect(데이터1, 데이터2)
- x, y사이의 교집합을 구해준다.
- intersect는 함수가 겹쳐 따로 패키지이름을 통해 사용했다.

16-2. setdiff(데이터1, 데이터2)
- 데이터1 - 데이터2의 차집합을 구해준다.

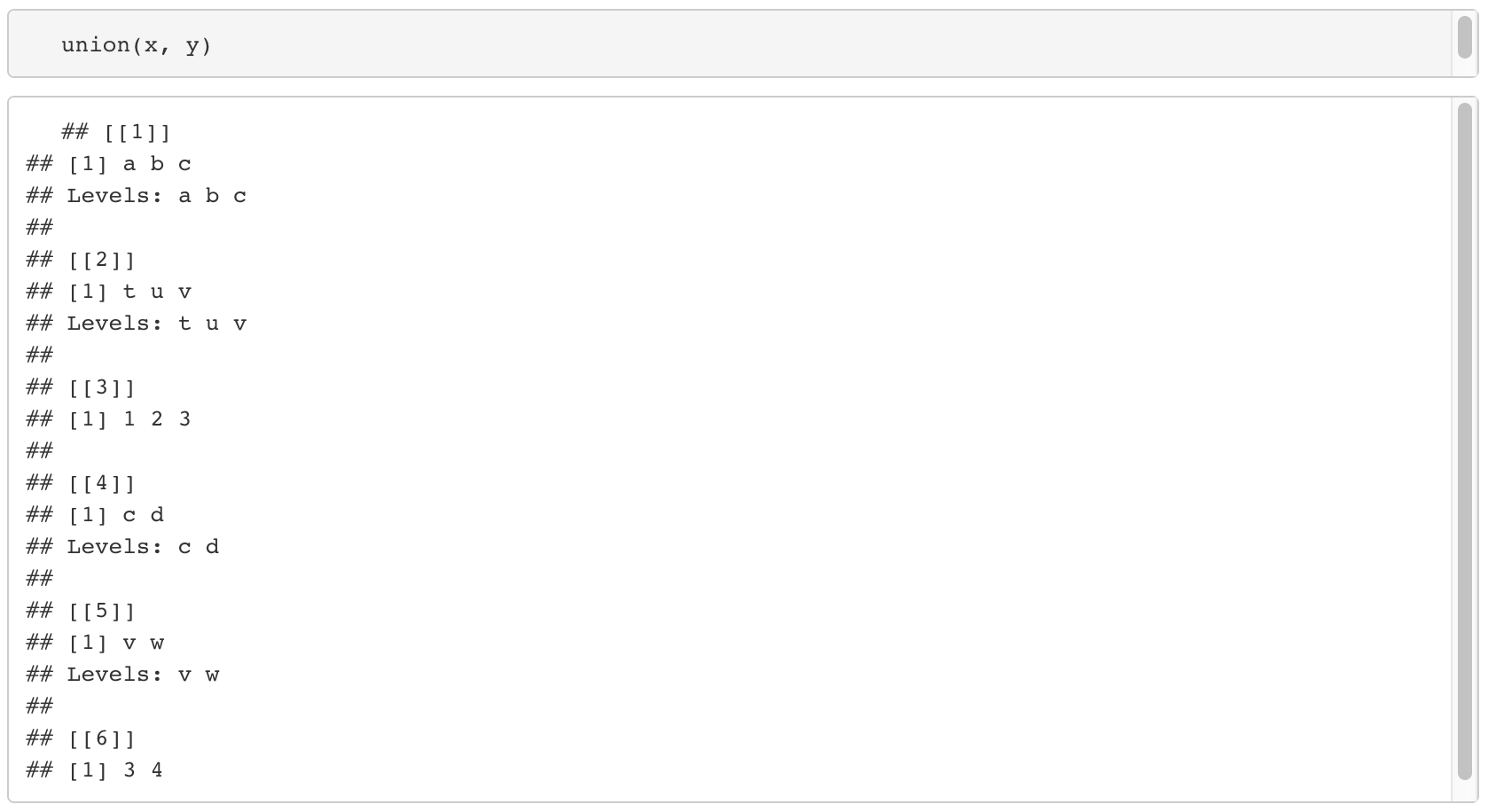
16-3. union(데이터1, 데이터2)
- 데이터1과 데이터2의 합집합을 구해준다.
반응형
'Programming Language > R' 카테고리의 다른 글
| stringr (0) | 2019.09.01 |
|---|---|
| forcats (0) | 2019.07.15 |
| tidyr (0) | 2019.07.10 |
댓글